项目缘由:
公司一直有一个半死不活的爬虫系统,在爬取着市面上竞争公司官网的一些活动、文章等内容。
由于该系统的开发人员已离职快两年,多次经手,现已基本失去爬取能力,每周的报表都得靠人工汇总。
在我们这个以移民业务为主,IT部门隶属于后勤服务的所谓的大企业的子公司里面,英勇的前任leader满口答应高层可以对这个系统进行重新规划改造,来support公司业务(主要就是爬取别人家的活动信息,自己的销售悄悄跑过去抢客户,顺带爬取别人的优秀文章发在自己的相关产品里面...等等)。
好吧,这些本就与我无关。但可怜的我躲角落里还是中枪了,前任leader几个关键词一列,会议上随便一吹,这个伟大而光荣的任务就落在我头上了......
最主要是我手上还有其他小矮人(介绍一下:我们这个服务型IT部门,有“一个白雪公主,10几个小矮人”的项目需要支持)在进行中。
申请人员,没有!申请资源,没有!申请需求,没有!什么?现有爬虫项目的交接?能找到源码就不错了,要啥交接!...
本就不堪一击的一件事,偶遇leader在项目启动前离职(所以叫前任),独剩我一个人孤苦伶仃。
当然,我们出来混程序的,有所为有所不为!抱怨过后,该干还得干,心里还得美滋滋的想着“这是领导们对我能力的一种信任”,都是为了生活啊...
程序员可以让步,却不可以退缩,可以羞涩,却不可以软弱,总之,程序员必须是勇敢的。
现有旧爬虫系统分析:
时间紧迫,简单的梳理了现有爬虫系统代码:
1.系统整体构架是一个权限管控系统,爬虫相关功能只占整体的20%不到(具体当时的缘由未知)
2.爬虫功能有两套方法共存:正则表达式与AngleSharp
3.代码基本规范,解析活动数据方法较死,冗余在爬取方法里面
贴两个主要类出来秀一秀,让它们也见见光,毕竟是以前的工程师花了心血的。
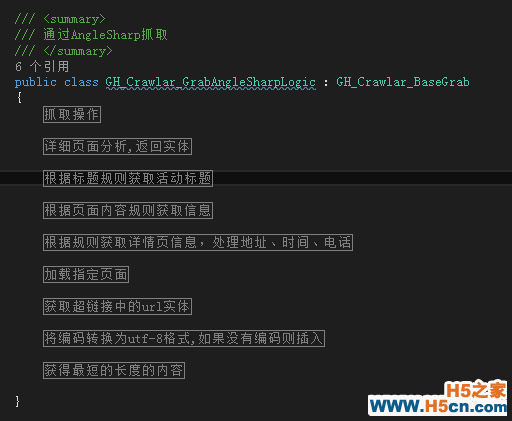
抓取详细页面 GrabPage(string Url, GH_Crawlar_GraspRule gH_Crawlar_GraspRule,string defaultXmlPath, string replaceStrXmlPath, string creator) 9 { { 12 HttpHelper httpHelper = new HttpHelper(); , EnumHelper.GetEnumDescription((Charset)gH_Crawlar_GraspRule.Charset)); , ""); , ).Split(); , ); 18 Regex regTilte = new Regex(titleRule.Trim(), RegexOptions.Singleline); titlt = StringHelper.ClearHtml(regTilte.Match(result).Value.ToString()); 21 Regex mainRegex = new Regex(gH_Crawlar_GraspRule.MainRule.Trim(), RegexOptions.Singleline); 22 string _Content = mainRegex.Match(result).Value; 23 24 _Content = StringHelper.Filter(_Content); address = string.Empty; 27 string city = string.Empty; 28 string time = string.Empty; 29 string tel = string.Empty; 30 string didian = string.Empty; 31 string dizhi = string.Empty; 32 //pkid ==1 33 //if (article.Pkid == 1) titlt2 = StringHelper.ClearHtml(regTilte.Match(_Content).Value.ToString()); (!string.IsNullOrEmpty(titlt2)) 38 { 39 titlt = titlt2; 40 } (!string.IsNullOrEmpty(titlt)) 44 { 45 foreach (string temp in strTemp) 46 { 47 if (!string.IsNullOrEmpty(temp)) 48 { 49 titlt = titlt.Replace(temp, ""); 50 } 51 } 52 } [] obj = GetFilter(_Content, defaultXmlPath, replaceStrXmlPath); 55 56 address = obj[0]; 57 time = obj[1]; 58 tel = obj[2]; region = (int)Regional.Other; 62 city = GetArea(titlt, address, out region); GH_Crawlar_GraspInfo gH_Crawlar_GraspInfo = new GH_Crawlar_GraspInfo(); 66 GH_Crawlar_GraspInfoLogic gH_Crawlar_GraspInfoLogic = new GH_Crawlar_GraspInfoLogic(); List<string> times = GetTimes(time); 70 gH_Crawlar_GraspInfo.FullTime = time; 71 gH_Crawlar_GraspInfo.StartDay = string.IsNullOrEmpty(times[0]) ? "" : times[0]; 72 gH_Crawlar_GraspInfo.StartTime = string.IsNullOrEmpty(times[1]) ? "" : times[1]; 73 gH_Crawlar_GraspInfo.WeakDate = string.IsNullOrEmpty(times[2]) ? "" : times[2]; 74 gH_Crawlar_GraspInfo.Title = titlt.Trim(); 75 gH_Crawlar_GraspInfo.Url = Url; 76 gH_Crawlar_GraspInfo.Region = region; : address; 78 gH_Crawlar_GraspInfo.Area = city; 79 gH_Crawlar_GraspInfo.ArticleType = GetType(titlt.Trim()); 80 gH_Crawlar_GraspInfo.DistributionGroup = GetsSelas(city); 81 gH_Crawlar_GraspInfo.Tel = string.IsNullOrEmpty(tel) ? gH_Crawlar_GraspRule.Telephone : tel; 82 gH_Crawlar_GraspInfo.Creator = creator; 83 gH_Crawlar_GraspInfo.CreateTime = DateTime.Now; 84 gH_Crawlar_GraspInfo.CatalogID = gH_Crawlar_GraspRule.CatalogID; 85 gH_Crawlar_GraspInfo.State = (int)State.Enable; 86 gH_Crawlar_GraspInfo.FullContent = result; 87 gH_Crawlar_GraspInfo.Deleted = false; 88 gH_Crawlar_GraspInfo.RuleID = gH_Crawlar_GraspRule.RuleID; (!string.IsNullOrEmpty(titlt)) 92 { 93 List<GH_Crawlar_GraspInfo> gH_Crawlar_GraspInfos = gH_Crawlar_GraspInfoLogic.GetAll(x => 94 x.RuleID == gH_Crawlar_GraspInfo.RuleID && 95 x.Title == titlt.Trim() && 96 x.Address == gH_Crawlar_GraspInfo.Address && 97 x.FullTime == time && 98 x.Deleted == false).ToList(); 99 if (gH_Crawlar_GraspInfos.Count == 0) 100 { 101 gH_Crawlar_GraspInfoLogic.Add(gH_Crawlar_GraspInfo); 102 } 103 } 104 } 105 catch (Exception ex) 106 { 107 throw ex; 108 } }
View Code
编程是一种单调的生活,因此程序员比普通人需要更多的关怀,更多的友情。
新爬虫系统规划:
公司懂这一方面的人几乎没有,我也仅限于在博客园偶尔看看各位大拿的相关文章,自己也就给自己的小网站爬过点美女图片...
要真说到一个企业级的爬虫系统,我想整体规划里面爬虫相关占比应该不到30%才对。
毕竟,公司做一个爬虫系统的目的绝不是为了简单的爬取一些数据。
我分析的一个企业级的爬虫系统应该具有的主体功能如下(还请各位资深人士多多指教):
1.爬取指定数据
2.规则化爬取到的数据(这一点很重要,就像我们爬取到的活动类文章,是需要在内容中准确提炼出活动时间、活动地点、参会人数、活动类别、主讲嘉宾等信息的)
3.数据报表分析、自动邮件订阅推送
4.文章全文检索(活动以外的文章数据,可以作为整个行业的时讯基库存在,将成为企业其他网站、微信等文章资源的来源)
5.基本统计分析
6.辅助决策支持(当然,这一点肯定是大BOSS门提出来的啦~~)
在与boss碰头一两次后,做了这个系统的第一份头脑风暴图:
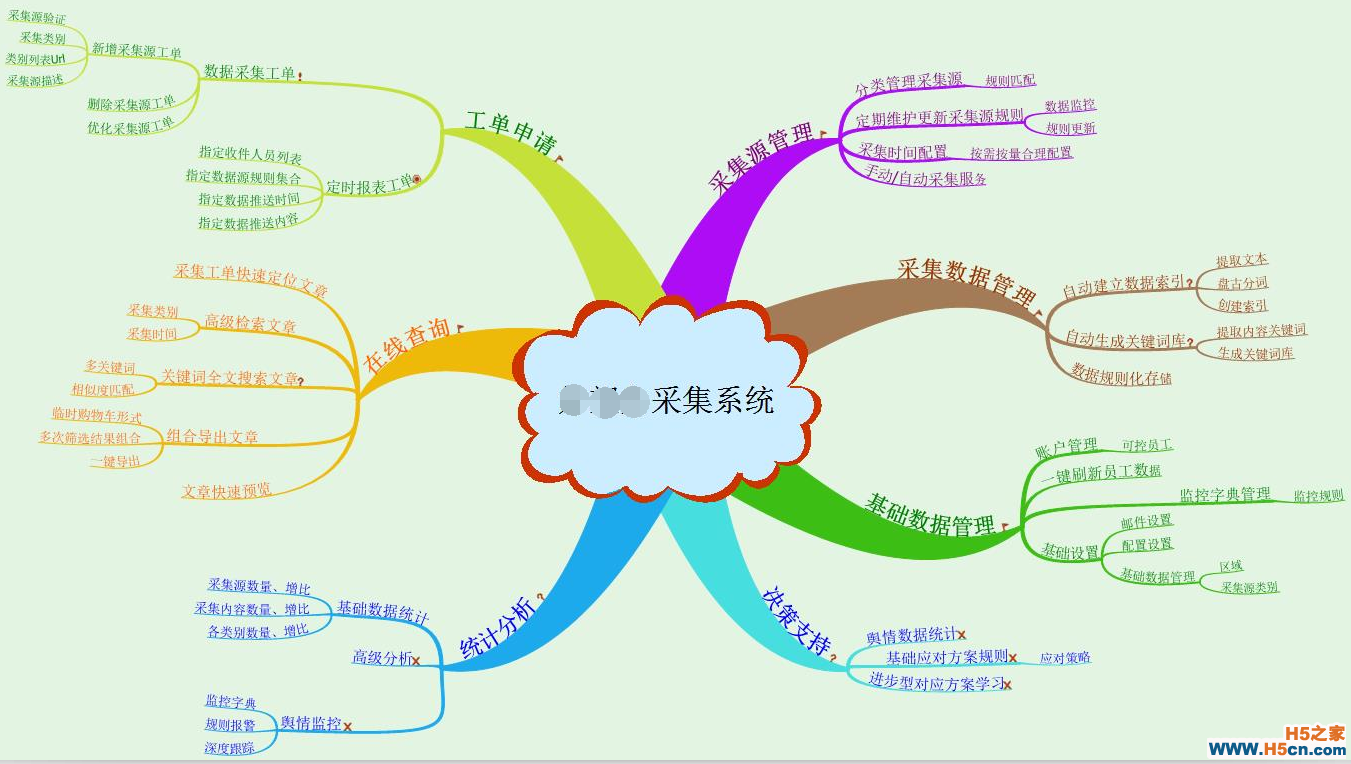
经过一番讲解与讨论(我也不确定,boss们是否听明白了我的方案),boss们拍板“没啥大问题,给你一个月自己去做吧,做完拿出来给我们用”。
对,你没听错,就是一个月,还是在我手上有其他项目,并且不给任何资源的情况下,当时就泪崩在现场!
不过上有政策,下有对策,人总不能被尿憋死!
于是乎过了两天,我又新给出了更具体的方案:
1.新系统职能主要是数据支持,不再是单一的爬虫系统,取了一个高大上的名字“Support云”
2.抽象的数据处理流程图
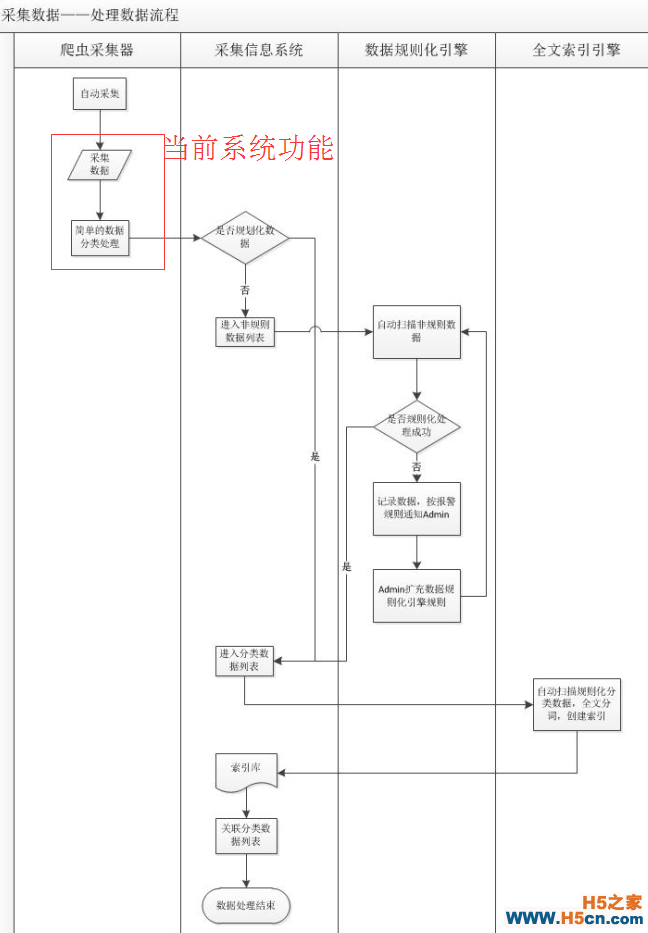
3.对boss更加抽象的最终服务方案图
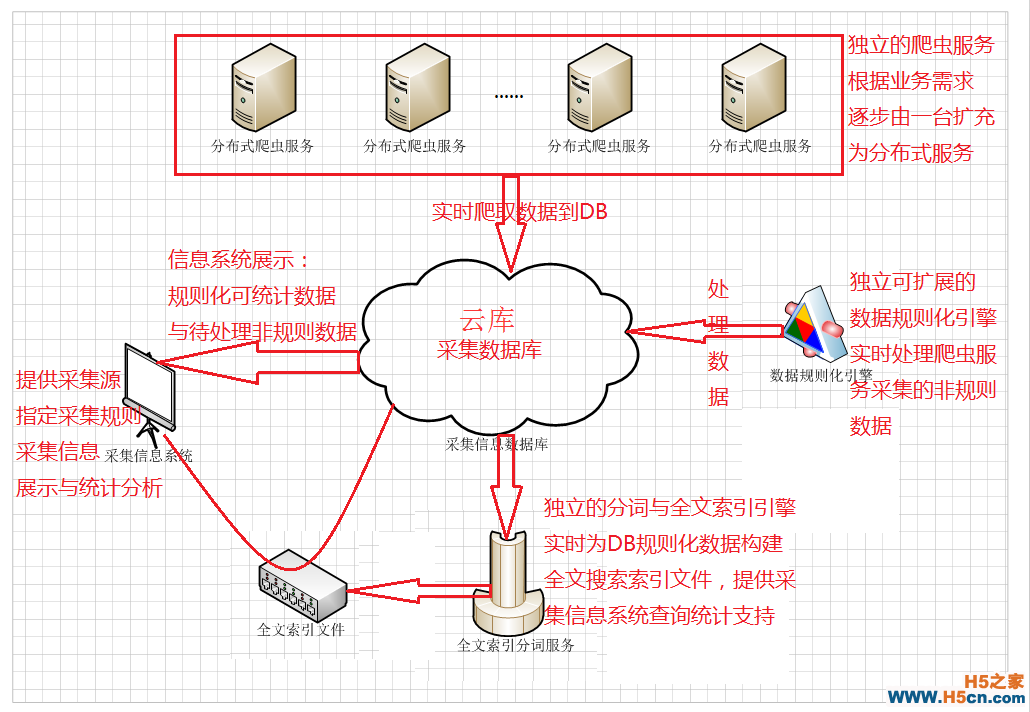
再配上一张规划排期的excel表格。顺利的与boss畅谈个把小时,最终确定按我的排期,第一个月只做排期表的第一版功能。
欧耶~~目的终于达到,不然稳妥妥的自己把自己加班加死最后还捞不着好!
非优秀的程序员常常把空间和时间消耗殆尽,优秀的程序员则总是有足够的空间和时间去完成编程任务,而且配合近乎完美。
项目进展:
当前已正式启动,博主已开始进行新爬虫系统项目的搭建。
每周都会发一篇博客记录相关的方案与框架代码,直至项目最终上线,欢迎大家来吐槽~~~

我们应该重视团队的精神,一个人作用再大,也不过是一碗水中比较大的一粒水珠而已。
这句话送给现在的boss!!!
原创文章,代码都是从自己项目里贴出来的。转载请注明出处哦,亲~~~
 相关文章
相关文章

 精彩导读
精彩导读
 热门资讯
热门资讯 关注我们
关注我们
