�����������ǰ������㷨�IJ���ѧϰ���̣���ѧϰ�Ĺ����У����ϸ��� HMM �IJ������Ӷ�ʹ�� P(O | ��) ������Ǽ����ʼ�� HMM ����Ϊ ��={ ��, A, B }�����ȼ���ǰ����� �� �ͺ������ �£��ٸ��ݸոս��ܵĹ�ʽ�������� �� �� �ƣ�����������3���ع��ƹ�ʽ���� HMM ������
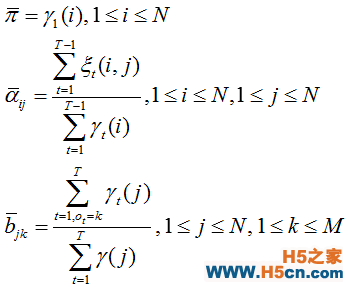
����������Ƕ��嵱ǰ�� HMM ģ��Ϊ ��={ �У�A��B }����ô�������ø�ģ�ͼ�����������ʽ�ӵ��Ҷˣ������ٶ������¹��Ƶ� HMM ģ��Ϊ����ô��������ʽ�ӵ���˾����ع��� HMM ģ�Ͳ�����Baum ������ͬ����70���֤���ˣ����������ǵ����ؼ�����������ʽ�ӣ��ɴ˲��ϵ����¹��� HMM �IJ�������ô�ڶ�ε�������Եõ� HMM ģ�͵�һ�����似Ȼ���ơ�������Ҫע����ǣ�ǰ������㷨���õ�������似Ȼ������һ���ֲ����Ž⡣
�����ο����ϣ�
����1.
����2.
����3.
����4. Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77 (2), p. 257�C286, February 1989.
����5. L. R. Rabiner and B. H. Juang, ��An introduction to HMMs,�� IEEE ASSP Mag., vol. 3, no. 1, pp. 4-16, 1986.
����6. ~gerjanos/HMM/node2.html
����7.
����8. �������ɷ�ģ�ͼ�飬��Ⱥ
�� 1 �� 0
�ҵ�ͬ������
��������
�鿴����
* �����û�����ֻ��������˹۵㣬������CSDN��վ�Ĺ۵������
��������

likelet

���֣�1640
��������
���·���
���´浵
�Ķ�����
��
 �������
�������
 ���ʵ���
���ʵ���
 ������Ѷ
������Ѷ ��ע����
��ע����
