因为在初始的时候,状态 j 的概率不仅和这个状态本身相关,还和观察状态有关,所以这里用到了混淆矩阵的值,k1 表示第一个观察状态,bjk1 表示隐藏状态是 j,但是观察成 k1 的概率。
3) 计算 t>1 时候的部分概率
还是看计算部分概率的公式是:αt(j) = Pr(观察状态 | 隐藏状态 j) x Pr(t 时刻到达状态 j 的所有路径)。 这个公式的左边是从混淆矩阵中已知的,我只需要计算右边部分,很显然右边是所有路径的和:
需要计算的路径数是和观察序列的长度的平方相关的,但是 t 时刻的部分概率已经计算过了之前的所有路径,所以在 t+1 时刻只需要根据 t 时刻的概率来计算就可以了:

这里简单解释下,bjk(t+1) 就是在 t+1 时刻的第 j 个隐藏状态被认为是当前的观察状态的概率,后面一部分是所有t时刻的隐藏状态到 t+1 时候的隐藏状态j的转移的概率的和。这样我们每一步的计算都可以利用上一步的结果,节省了很多时间。
4) 公式推导
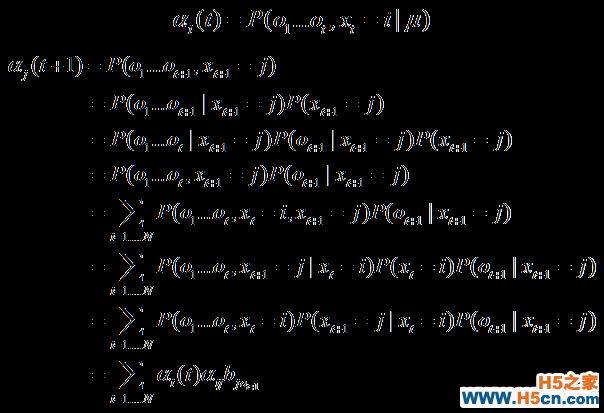
5) 降低计算复杂度
我们可以比较穷举和递归算法的复杂度。假设有一个 HMM,其中有 n 个隐藏状态,我们有一个长度为 T 的观察序列。
穷举算法的需要计算所有可能的隐藏序列:
需要计算:
很显然穷举算法的时间开销是和 T 指数相关的,即 NT,而如果采用递归算法,由于我们每一步都可以利用上一步的结果,所以是和 T 线性相关的,即复杂度是 N2T。
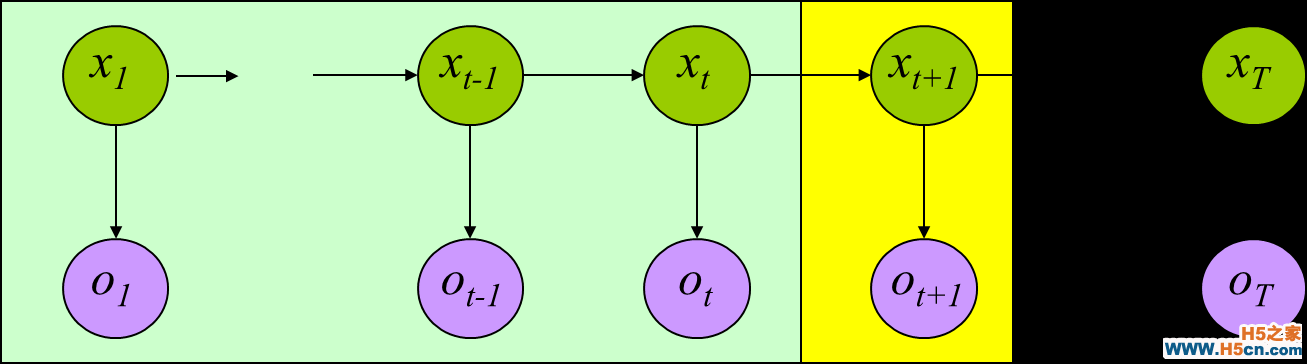
这里我们的目的是在某个给定的 HMM 下,计算出某个可观察序列的概率。我们通过先计算部分概率的方式递归的计算整个序列的所有路径的概率,大大节省了时间。在 t=1 的时候,使用了初始概率和混淆矩阵的概率,而在t时刻的概率则可以利用 t-1 时刻的结果。
这样我们就可以用递归的方式来计算所有可能的路径的概率和,最后,所有的部分概率的计算公式为
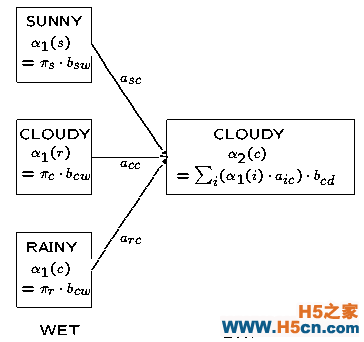
使用天气的例子,计算 t=2 时刻的 cloudy 状态的概率方法如图:
我们使用前向算法在给定的一个 HMM 下计算某个可观察序列的概率。前向算法主要采用的是递归的思想,利用之前的计算结果。有了这个算法,我们就可以在一堆 HMM 中,找到一个最满足当前的可观察序列的模型(前向算法计算出来的概率最大)。
(二) 根据可观察状态的序列找到一个最可能的隐藏状态序列
和上面一个问题相似的并且更有趣的是根据可观察序列找到隐藏序列。在很多情况下,我们对隐藏状态更有兴趣,因为其包含了一些不能被直接观察到的有价值的信息。比如说在海藻和天气的例子中,一个隐居的人只能看到海藻的状态,但是他想知道天气的状态。这时候我们就可以使用 Viterbi 算法来根据可观察序列得到最优可能的隐藏状态的序列,当然前提是已经有一个 HMM。
另一个广泛使用 Viterbi 算法的领域是自然语言处理中的词性标注。句子中的单词是可以观察到的,词性是隐藏的状态。通过根据语句的上下文找到一句话中的单词序列的最有可能的隐藏状态序列,我们就可以得到一个单词的词性(可能性最大)。这样我们就可以用这种信息来完成其他一些工作。
下面介绍一下维特比算法 (Viterbi Algorithm)
一.如何找到可能性最大的隐藏状态序列?
通常我们都有一个特定的 HMM,然后根据一个可观察状态序列去找到最可能生成这个可观察状态序列的隐藏状态序列。
1. 穷举搜索
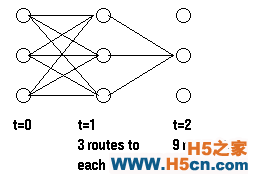
我们可以在下图中看到每个隐藏状态和可观察状态的关系。
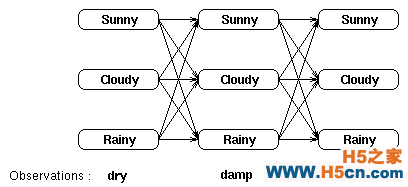
通过计算所有可能的隐藏序列的概率,我们可以找到一个可能性最大的隐藏序列,这个可能性最大的隐藏序列最大化了 Pr(观察序列 | 隐藏状态集)。比如说,对于上图中的可观察序列 (dry damp soggy),最可能的隐藏序列就是下面这些概率中最大的:
Pr(dry, damp, soggy | sunny, sunny, sunny), ……,Pr(dry, damp, soggy | rainy, rainy, rainy)
这个方法是可行的,但是计算代价很高。和前向算法一样,我们可以利用转移概率在时间上的不变性来降低计算的复杂度。
2. 使用递归降低复杂度
 相关文章
相关文章
 精彩导读
精彩导读
 热门资讯
热门资讯 关注我们
关注我们
