例如,我们也许有一个海藻的“Summer”模型和一个“Winter”模型,因为海藻在夏天和冬天的状态应该是不同的,我们希望根据一个可观察状态(海藻的潮湿与否)序列来判断现在是夏天还是冬天。
我们可以使用前向算法来计算在某个特定的 HMM 下一个可观察状态序列的概率,然后据此找到最可能的模型。
这种类型的应用通常出现在语音设别中,通常我们会使用很多 HMM,每一个针对一个特别的单词。一个可观察状态的序列是从一个可以听到的单词向前得到的,然后这个单词就可以通过找到满足这个可观察状态序列的最大概率的 HMM 来识别。
下面介绍一下前向算法 (Forward Algorithm)
如何计算一个可观察序列的概率?
1. 穷举搜索
给定一个 HMM,我们想计算出某个可观察序列的概率。考虑天气的例子,我们知道一个描述天气和海藻状态的 HMM,而且我们还有一个海藻状态的序列。假设这个状态中的某三天是(dry,damp,soggy),在这三天中的每一天,天气都可能是晴朗,多云或者下雨,我们可以用下图来描述观察序列和隐藏序列:

在这个图中的每一列表示天气的状态可能,并且每个状态都指向相邻的列的每个状态,每个状态转换在状态转移矩阵中都有一个概率。每一列的下面是当天的可观察的海藻的状态,在每种状态下出现这种可观察状态的概率是由混淆矩阵给出的。
一个可能的计算可观察概率的方法是找到每一个可能的隐藏状态的序列,这里有32 = 27种,这个时候的可观察序列的概率就是 Pr(dry, damp, soggy | HMM)=Pr(dry, damp, soggy | sunny, sunny, sunny) + . . . . + Pr(dry, damp, soggy | rainy, rainy, rainy)。
很显然,这种计算的效率非常低,尤其是当模型中的状态非常多或者序列很长的时候。事实上,我们可以利用概率不随时间变化这个假设来降低时间的开销。
2. 使用递归来降低复杂度
我们可以考虑给定 HMM 的情况下,递归的计算一个可观察序列的概率。我们可以首先定义一个部分概率,表示达到某个中间状态的概率。接下来我们将看到这些部分概率是如何 在time=1 和 time = n (n > 1) 的时候计算的。
假设一个T时间段的可观察序列是:
1) 部分概率
下面这张图表示了一个观察序列(dry,damp,soggy)的一阶转移

我们可以通过计算到达某个状态的所有路径的概率和来计算到达某个中间状态的概率。比如说,t=2时刻,cloudy的概率用三条路径的概率之和来表示:

我们用 αt(j) 来表示在 t 时刻是状态 j 的概率,αt(j)=Pr(观察状态 | 隐藏状态 j ) x Pr(t 时刻到达状态 j 的所有路径)。
最后一个观察状态的部分概率就表示了整个序列最后达到某个状态的所有可能的路径的概率和,比如说在这个例子中,最后一列的部分状态是通过下列路径计算得到的:
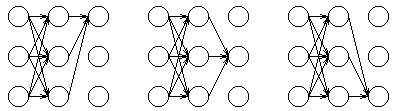
因为最后一列的部分概率是所有可能的路径的概率和,所以就是这个观察序列在给定 HMM 下的概率了。
2) 计算 t=1时候的部分概率
当 t=1 的时候,没有路径到某个状态,所以这里是初始概率,Pr(状态 j | t=0) = π(状态 j ),这样我们就可以计算 t=1 时候的部分概率为:
 相关文章
相关文章
 精彩导读
精彩导读
 热门资讯
热门资讯 关注我们
关注我们
