注意,一个整数可能用几种类型来提取,而无需转换。例如,一个名为 x 的 Value 包含 123,那么 x.IsInt() == x.IsUint() == x.IsInt64() == x.IsUint64() == true。但如果一个名为 y 的 Value 包含 -3000000000,那么仅会令 x.IsInt64() == true。
当要提取 Number 类型,GetDouble() 是会把内部整数的表示转换成 double。注意 int 和 unsigned 可以安全地转换至 double,但 int64_t 及 uint64_t 可能会丧失精度(因为 double 的尾数只有 52 位)。
查询 String除了 GetString(),Value 类也有一个 GetStringLength()。这里会解释个中原因。
根据 RFC 4627,JSON String 可包含 Unicode 字符 U+0000,在 JSON 中会表示为 "\\u0000"。问题是,C/C++ 通常使用空字符结尾字符串(null-terminated string),这种字符串把 `\0' 作为结束符号。
为了符合 RFC 4627,RapidJSON 支持包含 U+0000 的 String。若你需要处理这些 String,便可使用 GetStringLength() 去获得正确的字符串长度。
例如,当解析以下的 JSON 至 Document d 之后:
{ "s" : "a\u0000b" }
"a\\u0000b" 值的正确长度应该是 3。但 strlen() 会返回 1。
GetStringLength() 也可以提高性能,因为用户可能需要调用 strlen() 去分配缓冲。
此外,std::string 也支持这个构造函数:
string(const char* s, size_t count);
此构造函数接受字符串长度作为参数。它支持在字符串中存储空字符,也应该会有更好的性能。
比较两个 Value你可使用 == 及 != 去比较两个 Value。当且仅当两个 Value 的类型及内容相同,它们才当作相等。你也可以比较 Value 和它的原生类型值。以下是一个例子。
if (document["hello"] == document["n"]) /*...*/; // 比较两个值
if (document["hello"] == "world") /*...*/; // 与字符串家面量作比较
if (document["i"] != 123) /*...*/; // 与整数作比较
if (document["pi"] != 3.14) /*...*/; // 与 double 作比较
Array/Object 顺序以它们的元素/成员作比较。当且仅当它们的整个子树相等,它们才当作相等。
注意,现时若一个 Object 含有重复命名的成员,它与任何 Object 作比较都总会返回 false。
创建/修改值有多种方法去创建值。 当一个 DOM 树被创建或修改后,可使用 Writer 再次存储为 JSON。
改变 Value 类型当使用默认构造函数创建一个 Value 或 Document,它的类型便会是 Null。要改变其类型,需调用 SetXXX() 或赋值操作,例如:
d; // Null
d.SetObject();
v; // Null
v.SetInt(10);
v = 10; // 简写,和上面的相同
构造函数的各个重载几个类型也有重载构造函数:
b(true); // 调用 Value(bool)
i(-123); // 调用 Value(int)
u(123u); // 调用 Value(unsigned)
d(1.5); // 调用 Value(double)
要重建空 Object 或 Array,可在默认构造函数后使用 SetObject()/SetArray(),或一次性使用 Value(Type):
o();
a();
转移语义(Move Semantics)在设计 RapidJSON 时有一个非常特别的决定,就是 Value 赋值并不是把来源 Value 复制至目的 Value,而是把把来源 Value 转移(move)至目的 Value。例如:
a(123);
b(456);
b = a; // a 变成 Null,b 变成数字 123。
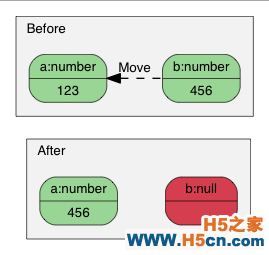
使用移动语义赋值。
为什么?此语义有何优点?
最简单的答案就是性能。对于固定大小的 JSON 类型(Number、True、False、Null),复制它们是简单快捷。然而,对于可变大小的 JSON 类型(String、Array、Object),复制它们会产生大量开销,而且这些开销常常不被察觉。尤其是当我们需要创建临时 Object,把它复制至另一变量,然后再析构它。
例如,若使用正常 * 复制 * 语义:
o();
{
contacts();
// 把元素加进 contacts 数组。
// ...
o.AddMember("contacts", contacts, d.GetAllocator()); // 深度复制 contacts (可能有大量内存分配)
// 析构 contacts。
}
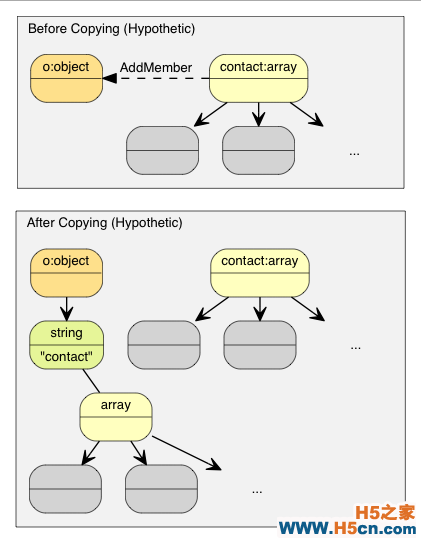
复制语义产生大量的复制操作。
那个 o Object 需要分配一个和 contacts 相同大小的缓冲区,对 conacts 做深度复制,并最终要析构 contacts。这样会产生大量无必要的内存分配/释放,以及内存复制。
有一些方案可避免实质地复制这些数据,例如引用计数(reference counting)、垃圾回收(garbage collection, GC)。
 相关文章
相关文章


![JsBin[使用教程]](/upload8/allimg/161017/13023G619_lit.png)
 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
