�������ߣ� Jonathan Fenocchi
����ʱ�䣺2005.10.26
�������ߣ�Sheneyan
����Ӣ��ԭ�ģ�
�������У��������������ͨ��javascript��һ��Զ��XML�ļ���ȡ�����ݡ�����ƪ�����У����ǽ�ѧ�������������������ӵĴ�������Ϊһ��ʾ�������ǻ���һ��XML���ݣ������ݷָ�ɶ�����Ƭ�ϲ��Բ�ͬ�ķ�ʽչʾ��ЩƬ�ϣ�ȡ������������α���ʶ�ģ���
������ƪ�����ǽ�������һƪ�����й����ʾ������Ļ���֮�ϣ���������㲻�������������ڵĴ��룬����Իع�ͷȥ����һƪ���£�sheneyanע���������棩��
��ʼ��
���������ǿ�ʼ���ǵĵ�һ��������XML��������дһ��XML�ĵ�������֯��һϵ������javascript���������ݣ��������ǽ�һ����֯һЩ�ڵ���ӽڵ㣨���ߣ�Ԫ�غ���Ԫ�أ����������������ǽ�ʹ��һЩ��ͥ��������֣�
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<pet>è</pet>
<pet>��</pet>
<pet>��</pet>
</pets>
</data>
���������棬���������XML��������������ĵ���һ��XML 1.0 �ĵ���ʹ��UTF-8���룩��һ����Ԫ�أ�<data>�����������е�Ԫ�������һ��һ��<pets>Ԫ����֯�����еij��Ȼ��һ��<pet>�ڵ��Ӧһֻ���Ϊ��ָ��ÿһֻ������ʲô���͵Ķ��������<pet>Ԫ�����������ı��ڵ㣺è�������㡣
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html lang="zh" dir="ltr">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>ʹ��Ajax����WebӦ�ó��� - ʾ��</title>
<script type="text/javascript"><!--
function ajaxRead(file){
var xmlObj = null;
if(window.XMLHttpRequest){
xmlObj = new XMLHttpRequest();
} else if(window.ActiveXObject){
xmlObj = new ActiveXObject("Microsoft.XMLHTTP");
} else {
return;
}
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
processXML(xmlObj.responseXML);
}
}
xmlObj.open ('GET', file, true);
xmlObj.send ('');
}
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var insertData = '<table><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].firstChild.data + '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
//--></script>
</head>
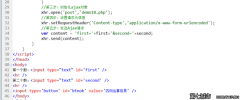
<body>
<h1>ʹ��Ajax����webӦ�ó���</h1>
<p>���ҳ����ʾ��AJAX�������ͨ����̬��ȡһ��Զ���ļ�������һ����ҳ�����ݣ�������Ҫ�κ���ҳ�����¼��ء�ע�⣺������Ӷ��ڽ�ֹjs���û���˵û��Ч����</p>
<p>���ҳ�潫��ʾ���ȡ�ز����������XML���ݡ���ȡ�ص����ݽ����Ա�����ʽ��������¡�
<a href="#">�鿴��ʾ</a>.</p>
<div></div>
</body>
</html>
��Sheneyanע����������ʾ���� ��XML�ļ�������
�������ע����Ǻ��ϴ�һ����ͬ���ķ�ʽ��ͨ��һ�������ӣ�����������������������ǽ����ݷ���һ��DIV������������������dataArea���������ajaxRead()�������ϴκܽӽ�������һ�㲻ͬ��onreadystatechange�������������ȿ�һ�����������
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
processXML(xmlObj.responseXML);
}
}
��������ȡ����updateObj��������һ������processXML()���º�����������������������õ�XML�ĵ�������Ҳ���DZ�ajaxRead����ȡ�صģ��������������⡰XML�ĵ���������ָ���Dz�����xmlObj.responseXML����
�������������Ƿ���һ���������processXML�����������Ĵ��룺
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var insertData = '<table><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].firstChild.data + '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
�������ȣ����Ƕ�����һЩ��������dataArray����Ϊ����<pet>�ڵ�����飨���ǽڵ����ݣ�ֻ�ǽڵ㣩����dataArrayLen�����������ij��ȣ��������ǵ�ѭ������insertData������һ������Ŀ�ͷ��HTML��
�������ǵĵڶ������DZ������е�<pet>Ԫ�أ�ͨ��������dataArray���������������ӵ�����insertData�С��������ǻᴴ��һ�������У�����һ���������ݽڵ�(td)��ȥ���ٽ�ÿһ��<pet>Ԫ�ص��ı�����������������ݽڵ㣬������Щ�����ӽ�������insertData������ˣ�ÿѭ��һ�Σ�����insertData������һ�а�������������֮һ���Ƶ������ݡ�
����������������������Dz���һ����</table>��������ǩ��������insertData������������������Ȼ����ֻʣ�����һ����������ǵ�Ŀ�꣺������Ҫ���������ŵ�ҳ���ϡ����˵��ǣ����ǵø�лinnerHTML���ԣ���ܼ�����ͨ������document.getElementById()ȡ��DIV��dataArea������������insertData���е�HTML���ȥ���ţ��������ð�����ˣ�
�������Ǽ���֮ǰ����
�����ҵ�ָ�����㣺
�������ȣ����ע����Dz�û��ʹ�ýڵ�<pets>��������Ϊ����ֻ��һ�������飨<pets>���Լ��������е�Ԫ�أ�ÿһ��<pet>Ԫ�أ�����Щ�ӽڵ�����˲�ͬ�����ݵ���������ͬ�����֡�����������У�����ڵ��ܹ������ԡ�Ȼ���������е�Ԫ��<pet>�Ž�<pets>Ԫ�ػ��DZȽϺã�����������Щ<pet>Ԫ���Լ�ɢ�ţ�����Ȼ��dataԪ�����棩��
��������һ�ַ�ʽ�Ǹ�ÿһ�������һ��ָ���ı�ǩ�����磺
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<è />
<�� />
<�� />
</pets>
</data>
����Ȼ�������ܹ�����Ԫ��<pets>��Ľڵ㡣���processXML��������������������
function processXML(obj){
var dataArray = obj.getElementsByTagName('pets')[0].childNodes;
var dataArrayLen = dataArray.length;
var insertData = '<table><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
if(dataArray[i].tagName){
insertData += '<tr><td>' + dataArray[i].tagName + '</td></tr>';
}
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
��Sheneyanע���ĺ��ʾ������ ��XML�ļ�������
��
 �������
�������

 ���ʵ���
���ʵ��� ������Ѷ
������Ѷ ��ע����
��ע����
