����MongoDb�ĸ�����������ʵ����ObjectId�������㷨������PyMongo����bson.objectid.py���档ͨ��ObjectId�������㷨�Լ�mongo shell��pymongo�����ӣ����ǿ��Կ�����objectid������������������ģ�������MongoDB��������������MongoDB������Ҳ�ﵽ��ȥ���Ļ������Ŀ�ġ�
�ṹ��ID˼����������Ľṹ��ID������ָ��һ��������ʱ�䡢�ռ䣨��������Ϣ���ɵ�ID��������ܵ�UUID�Լ����ֱ��ֶ����ڽṹ��id��
�����ṹ��ID���ŵ����ڳ������Ϣ�������õĿ϶���ʱ����Ϣ��ͨ��ID����ֱ���õ����ݵĴ���ʱ���ˣ����⣬��Ȼ�����������ݵķ��롣��Ȼ���������бף�������ID��Ϊ��Ƭ���ķ�Ƭ�����У����ID����ʱ����Ϣ����ô�ܿ����ڶ�ʱ�������ɵ����ݻ�����ͬһ����Ƭ���ڡ���������ѧϰ�ֲ�ʽϵͳ֮���ݷ�Ƭ��һ���У�������MongoDB��Ƭ�����ַ�ʽ��“hash partition”��“range partition“�����ʹ��ObjectId��Ϊsharding key����sharding��ʽΪrange partition����ô�����������ݵ�ʱ��ͻᵼ����������ͬһ��shard��������Ǵ���chunk��split��migration�����Dz�̫�õġ�
TFS�ļ���
��������ṹ��ID�а�����Ƭ��Ϣ���Ǿ����ˣ������Ͳ�����ά���������Ƭ����Ϣ������ֱ��ͨ��id�ҳ���Ӧ�ķ�Ƭ������������TFS������
����TFS���Ա��з��ķֲ�ʽ�ļ��洢ϵ����Ľṹһ���̶��ϲο���GFS��HDFS����Ԫ���ݷ�������֮ΪNameserver��ʵ�ʵ����ݴ洢��������֮ΪDataserver��TFS�����С�ļ��ϲ���һ�����ļ�����֮Ϊblock��block����ʵ�������洢��Ԫ����ˣ�DataServer����洢Block����NameServerά��block��DataServer��ӳ�䡣��ôС�ļ���block��ӳ���ϵ������ά���أ�Ҫ֪��С�ļ������Ǻܴ��
����TFS���ļ����ɿ�ź��ļ���ͨ��ij�ֶ�Ӧ��ϵ��ɣ����Ϊ18�ֽڡ��ļ����̶���T��ʼ���ڶ��ֽ�Ϊ�ü�Ⱥ�ı��(��������������ָ����ȡֵ��Χ 1~9)�����µ��ֽ���Block ID��File IDͨ��һ���ı��뷽ʽ�õ����ļ����ɿͻ��˳�����б���ͽ���
������ͼ��ʾ��
��������
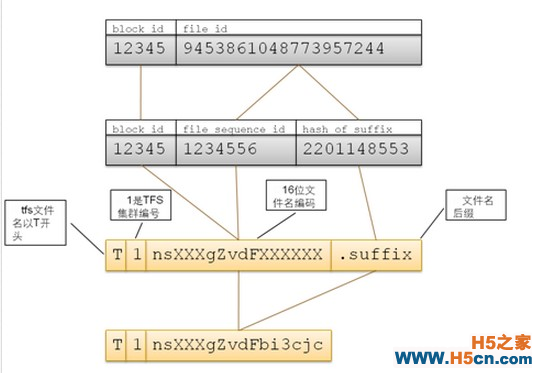
��������ͼ���Կ��������յ��ļ����ǰ�����block id��Ϣ�ĵģ���ô����������blockid��Ϣ�أ�����ͼ��ʾ��
��������
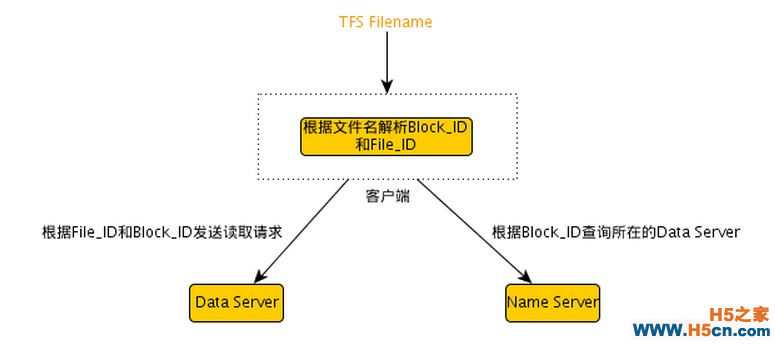
��������Ҫ�����ļ�����ȡ�ļ����ݵ�ʱ��TFS�Ŀͻ��ˣ�����ͨ���ļ���������Block id��File id��Ȼ���NameServer�ϸ���Block id��ѯblock���ڵ�DataServer��Ȼ���DataServer�ϸ���Block id�õ���Ӧ��block���ڸ���file id��block���ҵ���Ӧ���ļ���
����
����TFS���ڴ洢�Ա�������С�ļ���������Ʒ�ĸ��ֳߴ��СͼƬ����������Ƿdz���ģ�����õ�����Ԫ���ݷ�����ά���ļ������ļ���Ϣ��ӳ�䣬������Ƿdz���ġ���ʹ��Я��block id��Ϣ���ļ������ܺù����������⡣��ʹ������Я��������Ϣ��IDʱ����Ҫ���������ڷ���֮���Ǩ�������IDһ����˵ʹ���ܱ�ģ����IDӳ���Ӧ����һ��������������������������������
�ܽ�
���� ���Ľ����˷ֲ�ʽϵͳ�У�ȫ��ΨһID�����ɷ�����ID��Ҫ���������ͣ�һ������������ID����flicker�Ľ����������һ����Я��ʱ�䡢������Ϣ�����ID����uuid���ֲ�ʽϵͳ�У��õ�ȫ��ID�����㷨��������Ҫ���ⵥ�㣬�������Ҫ���Ļ�����Ļ����ã����⣬Я��ʱ����Ϣ����Ƭ��Ϣ��ID����ʵ�á�
referencesTicket Servers: Distributed Unique Primary Keys on the Cheap
UUID��Universally unique identifier��
rfc4122
Are you designing Primary Keys and ID’s???Well think twice..
TFS
��
 �������
�������


 ���ʵ���
���ʵ��� ������Ѷ
������Ѷ ��ע����
��ע����
