世间万物,都有自己唯一的标识,比如人,每个人都有自己的指纹(白夜追凶给我科普的,同卵双胞胎DNA一样,但指纹不一样)。又如中国人,每个中国人有自己的身份证。对于计算机,很多时候,也需要为每一份数据生成唯一的标识。在这里,数据的概念是非常宽泛的,比如数据量记录、文件、消息,而唯一的标识我们称之为id。
本文地址:
自增ID使用过mysql的同学应该都知道,经常用自增id(auto increment)作为主键,这是一个为long的整数类型,每插入一条记录,该值就会增加1,这样每条记录都有了唯一的id。自增id应该是使用最广泛的id生成方式,其优点在于非常简单、对数据库索引友好、而且也能透露出一些信息,比如当前有多少条记录(当然,用户也可能通过id猜出总共有多少用户,这就不太好)。但自增ID也有一些缺点:第一,id携带的信息太少,只能起到一个标识作用;第二,现在啥都是分布式的,如果多个mysql组成一个逻辑上的‘mysql’(比如水平分库这种情况),每个物理mysql都使用自增id,局部来说是唯一的,但总体来说就不唯一了。
于是乎,我们需要为分布式系统生成全局唯一的id。最简单的办法,部署一个单点,比如单独的服务(mysql)专门负责生成id,所有需要id的应用都通过这个单点获取一个唯一的id,这样就能保证系统中id的全局唯一性。但是分布式系统中最怕的就是单点故障(single point of failure),单点故障是可靠性、可用性的头号天敌,因此即使是中心化服务(centralized service)也会搞成一个集群,比如zookeeper。按照这个思路,就有了Flicker的解决方案。
Flicker的解决办法叫《Ticket Servers: Distributed Unique Primary Keys on the Cheap》,文章篇幅不长,而且通俗易懂,这里也有中文翻译。简单来说,Flicker是用两组(多组)mysql来提供全局id的生成,多组mysql避免了单点,那么怎么保证多组mysql生成的id全局唯一呢,这就利用了mysql的自增id以及replace into语法。
大家都知道mysql的自增id,但是不一定知道其实可以设置自增id的初始值以及自增步长, Flicker中的示例中,两个mysql(ticketserver)初始值分别是1和2,自增步长都是2(而不是默认值1),这样,ticketserver1永远生成奇数的id,而ticketserver2永远生成偶数的id。
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1
TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2
那么怎么获取这个id呢,不可能每需要一个id的时候都插入一条记录,这个时候就用到了replace into语法。 replace是insert、update的结合体,对于一条待插入的记录,如果其主键或者唯一索引的值已经存在表中的话,那么会删除旧的那条记录,然后插入新的记录;如果不存在,那么直接插入记录。这个非常类似mongodb中的findandmodify语法。在Flicker中,是这么使用的,首先schema如下:
CREATE TABLE `Tickets64` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM
注意,id是主键,而stub是唯一索引,当需要产生一个id的时候,使用以下sql语句;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
由于stub是唯一索引,当每次都插入‘a'的时候,会产生新的记录,而新记录的id是自增的(则增步长为2)
Flicker的解决办法通俗易懂,但还是没有解决id信息过少的问题,而且还是依赖单独的一组服务(mysql)来生成全局id。如果全局id的生成不依赖额外的服务,而且包含丰富的信息那就最好了。
携带时间与空间信息的ID UUID提到全局id,首先想到的肯定是UUID(Universally unique identifier),从名字就能看出,这个是专门用来生成全局id的。而UUID又分为多个版本,不同的语言,厂家都有自己的实现。本文对uuid的介绍主要参考rfc4122,如下图所示,一个uuid由一下部分组成:
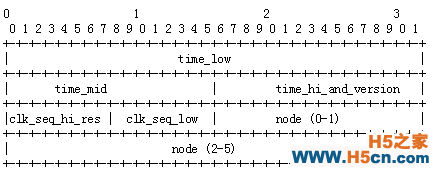
可以看到,uuid包含128个bit、即16个字节,其中包含了时间信息、版本号信息、机器信息。uuid也不是说一定能保证不冲突,但其冲突的概率小到可以忽略不计。使用uuid就不用再使用额外的id生成服务了。但缺点也有明显:太长,16个字节!太长有什么问题呢,占用空间?问题不大。主要的问题,是太长且随机的id对索引的不友好。在《Are you designing Primary Keys and ID’s???Well think twice..》一文中,作者也许需要用uuid来代替自增id,作者指出:
So what do we do change ID’s to UUID as well. Well no, that’s not a good idea because we will simply increase work for our database server. It will now have to index a random string of 128 bit. The data will be more fragmented and bigger to fit in memory. This will definitely bring down the performance of our system.
测试结果如下:

第一例是当前db中有多少条记录,第二列是使用uuid作为key时插入1 million条记录耗费的时间,第三列是使用64位的整形作为key时插入1 million条记录耗费的时间。从结果可以看出,随着数据规模增大,使用uuid时的插入速度远小于使用整形的情况。
既然uuid太长了,那后来者都是在uuid的基础上尽量缩短id的长度,使之更加实用。我认为,如果使用时间信息、机器信息来生成id的话,那么应该就是借鉴了uuid的做法,包含但不限于:twitter的snowflake,mongodb的。
MongoDB ObjectIdis a 12-byte type, constructed using:
objectid有12个字节,包含时间信息、机器表示、进程id、计数器。在mongo.exe中,通过ObjectId.getTimestamp可以获取时间信息
mongos> x = ObjectId()
ObjectId("59cf6033858d9d5a85caac02")
mongos> x.getTimestamp()
ISODate("2017-09-30T09:13:23Z")
 相关文章
相关文章


 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
