文件下载之断点续传(客户端与服务端的实现)
前面讲了文件的上传,今天来聊聊文件的下载。
老规矩,还是从最简单粗暴的开始。那么多简单算简单?多粗暴算粗暴?我告诉你可以不写一句代码,你信吗?直接把一个文件往IIS服务器上一扔,就支持下载。还TM么可以断点续传(IIS服务端默认支持)。
在贴代码之前先来了解下什么是断点续传(这里说的是下载断点续传)?怎么实现的断点续传?
断点续传就是下载了一半断网或者暂停了,然后可以接着下载。不用从头开始下载。
很神奇吗,其实简单得很,我们想想也是可以想到的。
首先客户端向服务端发送一个请求(下载文件)。然后服务端响应请求,信息包含文件总大小、文件流开始和结束位置、内容大小等。那具体是怎么实现的呢?
HTTP/1.1有个头属性Range。比如你发送请求的时候带上Range:0-199,等于你是请求0到199之间的数据。然后服务器响应请求Content-Range: bytes 0-199/250 ,表示你获取了0到199之间的数据,总大小是250。(也就是告诉你还有数据没有下载完)。
我们来画个图吧。
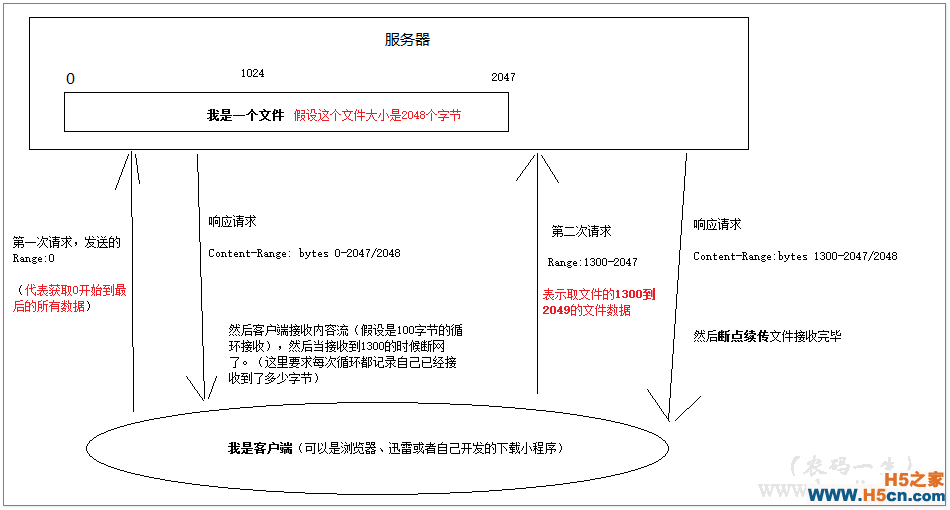
是不是很简单?这么神奇的东西也就是个“约定”而已,也就是所谓的HTTP协议。
然而,协议这东西你遵守它就存在,不遵守它就不存在。就像民国时期的钱大家都信它,它就有用。如果大部分人不信它,也就没卵用了。
这个断点续传也是这样。你服务端遵守就支持,不遵守也就不支持断点续传。所以我们写下载工具的时候需要判断响应报文里有没有Content-Range,来确定是否支持断点续传。
废话够多了,下面撸起袖子开干。
利用a标签来下载文件,也就是我们前面说的不写代码就可以实现下载。直接把文件往iis服务器上一扔,然后把链接贴到a标签上,完事。
<a href="/新建文件夹2.rar">下载</a>简单、粗暴不用说了。如真得这么好那大家也不会费力去写其他下载逻辑了。这里有个致命的缺点。这种方式提供的下载不够安全。谁都可以下载,没有权限控制,说不定还会被人文件扫描(好像csdn就出过这档子事)。
使用Response.TransmitFile提供文件下载上面说直接a标签提供下载不够安全。那我们怎么提供相对安全的下载呢。asp.net默认App_Data文件夹是不能被直接访问的,那我们把下载文件放这里面。然后下载的时候我们读取文件在返回到响应流。
//文件下载 public void FileDownload5() { //前面可以做用户登录验证、用户权限验证等。 string filename = "大数据.rar"; //客户端保存的文件名 string filePath = Server.MapPath("/App_Data/大数据.rar");//要被下载的文件路径 Response.ContentType = "application/octet-stream"; //二进制流 Response.AddHeader("Content-Disposition", "attachment;filename=" + filename); Response.TransmitFile(filePath); //将指定文件写入 HTTP 响应输出流 } 其他方式文件下载在网上搜索C#文件下载一般都会搜到所谓的“四种方式”。其实那些代码并不能拿来直接使用,有坑的。
第一种:(Response.BinaryWrite)
首先数组最大长度为int.MaxValue,然后正常程序是不会分这么大内存,很容易搞挂服务器。(也就是可以下载的文件,极限值最多也就2G不到。)【不推荐】
第二种:(Response.WriteFile)
public void FileDownload3() { string fileName = "新建文件夹2.rar";//客户端保存的文件名 string filePath = Server.MapPath("/App_Data/新建文件夹2.rar");//要被下载的文件路径 FileInfo fileInfo = new FileInfo(filePath); Response.Clear(); Response.ClearContent(); Response.ClearHeaders(); Response.AddHeader("Content-Disposition", "attachment;filename=\"" + HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8) + "\""); Response.AddHeader("Content-Length", fileInfo.Length.ToString());//文件大小 Response.AddHeader("Content-Transfer-Encoding", "binary"); Response.ContentType = "application/octet-stream"; Response.WriteFile(fileInfo.FullName);//大小参数必须介于零和最大的 Int32 值之间(也就是最大2G,不过这个操作非常耗内存) //这里容易内存溢出 Response.Flush(); Response.End(); }问题和第一种类似,也是不能下载大于2G的文件。然后下载差不多2G文件时,机器也是处在被挂的边缘,相当恐怖。【不推荐】
第三种:(Response.OutputStream.Write)
public void FileDownload4() { string fileName = "大数据.rar";//客户端保存的文件名 string filePath = Server.MapPath("/App_Data/大数据.rar");//要被下载的文件路径 if (System.IO.File.Exists(filePath)) { const long ChunkSize = 102400; //100K 每次读取文件,只读取100K,这样可以缓解服务器的压力 byte[] buffer = new byte[ChunkSize]; Response.Clear(); using (FileStream fileStream = System.IO.File.OpenRead(filePath)) { long fileSize = fileStream.Length; //文件大小 Response.ContentType = "application/octet-stream"; //二进制流 Response.AddHeader("Content-Disposition", "attachment; filename=" + HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8)); Response.AddHeader("Content-Length", fileStream.Length.ToString());//文件总大小 while (fileSize > 0 && Response.IsClientConnected)//判断客户端是否还连接了服务器 { //实际读取的大小 int readSize = fileStream.Read(buffer, 0, Convert.ToInt32(ChunkSize)); Response.OutputStream.Write(buffer, 0, readSize); Response.Flush();//如果客户端 暂停下载时,这里会阻塞。 fileSize = fileSize - readSize;//文件剩余大小 } } Response.Close(); } }这里明显看到了是在循环读取输出,比较机智。下载大文件时没有压力。【推荐】
 相关文章
相关文章


 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
