react-router 踩坑记
react-router踩坑分享 背景
有一个Web项目,采用的是前后端分离的方式,前端使用的是react技术栈,后端使用的是Django框架。
有这么需求: 在一个新闻列表里,点击某一条新闻,要求新闻详情页里的title keywords description是动态的。
辛苦历程 JavaScript动态修改当从后端取回数据时,用JavaScript动态改变title标签和meta标签就ok了。但是后来才发现,这个需求的目的是为了SEO,而爬虫可以爬到的数据是后端返回的html页面上的数据。如果是通过JavaScript来动态处理title keywords description的话,是不利于SEO的,因此,动态修改title keywords description只能放到后端做。后端将html拼接好,返回前端来,前端再进行相应的逻辑操作。
第一次尝试当思路理清楚之后,其实想着也就很简单, 三步就可以了。
然后开始进行测试:
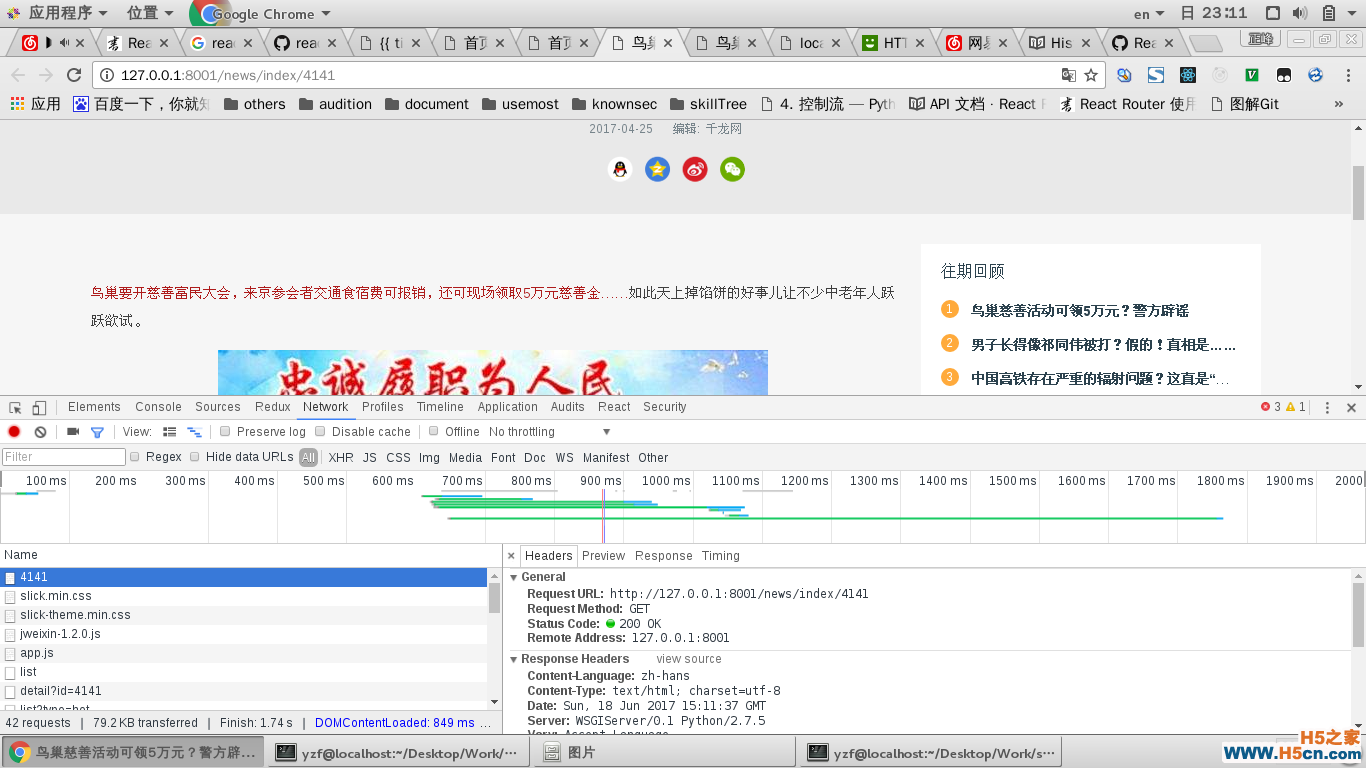
首先,打开主页面,点击任意一条新闻,此时的url还是hash模式的。
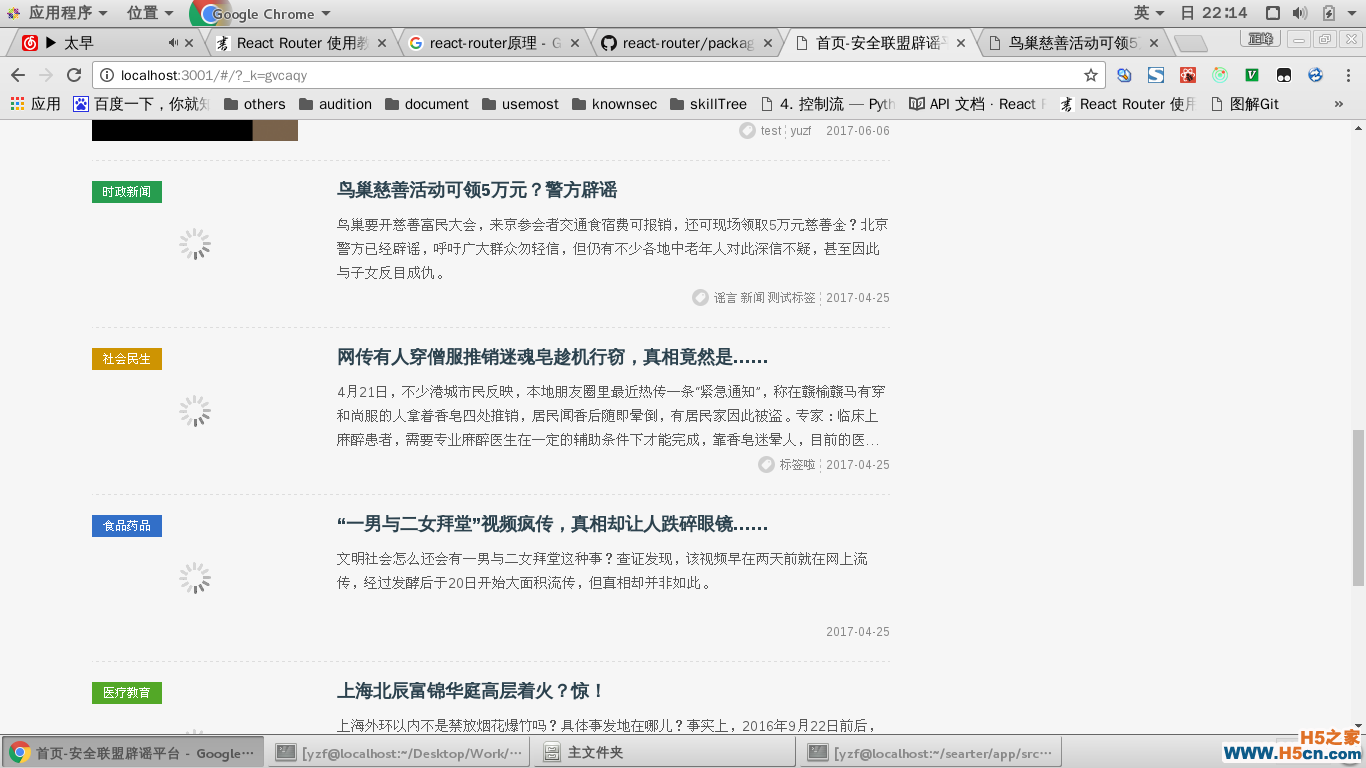
当跳到新闻详情页表的时候,打开控制台,进入Network, 查看所发送的请求。
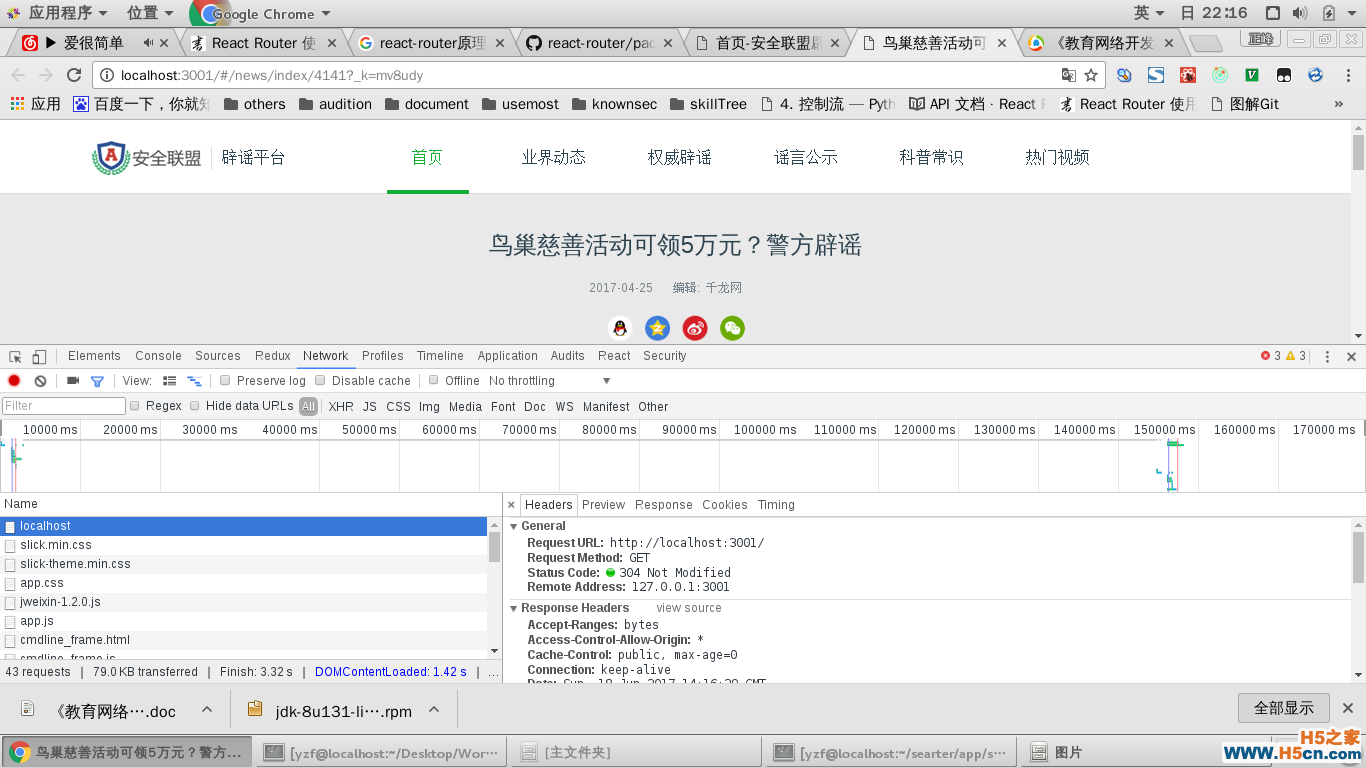
可以看见,请求的路径是localhost:3000, 也就是根目录,而后台配置的根路由的代码如下:
urlpatterns = [ url(r'^$', TemplateView.as_view(template_name='index.html'),), ]因此,可以知道,在请求后台的时候,后台返回了index.html模板回来。但是,问题出现了,我们想要返回的index.html里的keywords description title是在后端拼接好然后返回给前端,而目前我们所能实现的仅仅是返回一个index.html, 我们没办法改变那3个值,因为我们没有办法获取到前端的URL,或者说是前端没有办法传参数到后端去, 导致后端不能从数据库里查出来那三个值。
那么,现在需要解决的问题就是如何将参数传到后端去。
第二次尝试由于,点击某条新闻的时候,跳到新闻详情页的时候,这是浏览器主动去向后端发送的请求,因此是很难去控制这个过程的。
所以,有了下面这个解决方案: 既然很难在浏览器主动发请求的时候去控制参数的传递,那么就不用去控制。而是在浏览器返回了index.html后,这个时候,已经有了新闻的id, 因此就可以人为的控制再发一次请求,这个时候后端配置一个路由,根据id去数据库里查找keywords description title, 并在后端拼接好返回给前端。只不过有个缺点,会刷新一次页面。
但是,在实践的过程中,我理论上推导了一次整个过程,当人为控制发请求后,后端返回一个index.html, 然后又会执行js文件,然后又会发请求,然后又会返回index.html, 然后又会执行js文件,然后又会发请求。。。 就这样,一直循环下去,显然是不可能的。
第三次尝试这探索新的解决的方案的时候,了解了Http Header里的referer, 当浏览器向web服务器发送请求的时候,一般都会带上referer, 告诉服务器,我是从哪个连接来的。因为想着后端只要获取到了前端的URL,一切就搞定了,但是显而易见,referer依然不行。拿网易云音乐测试如下:
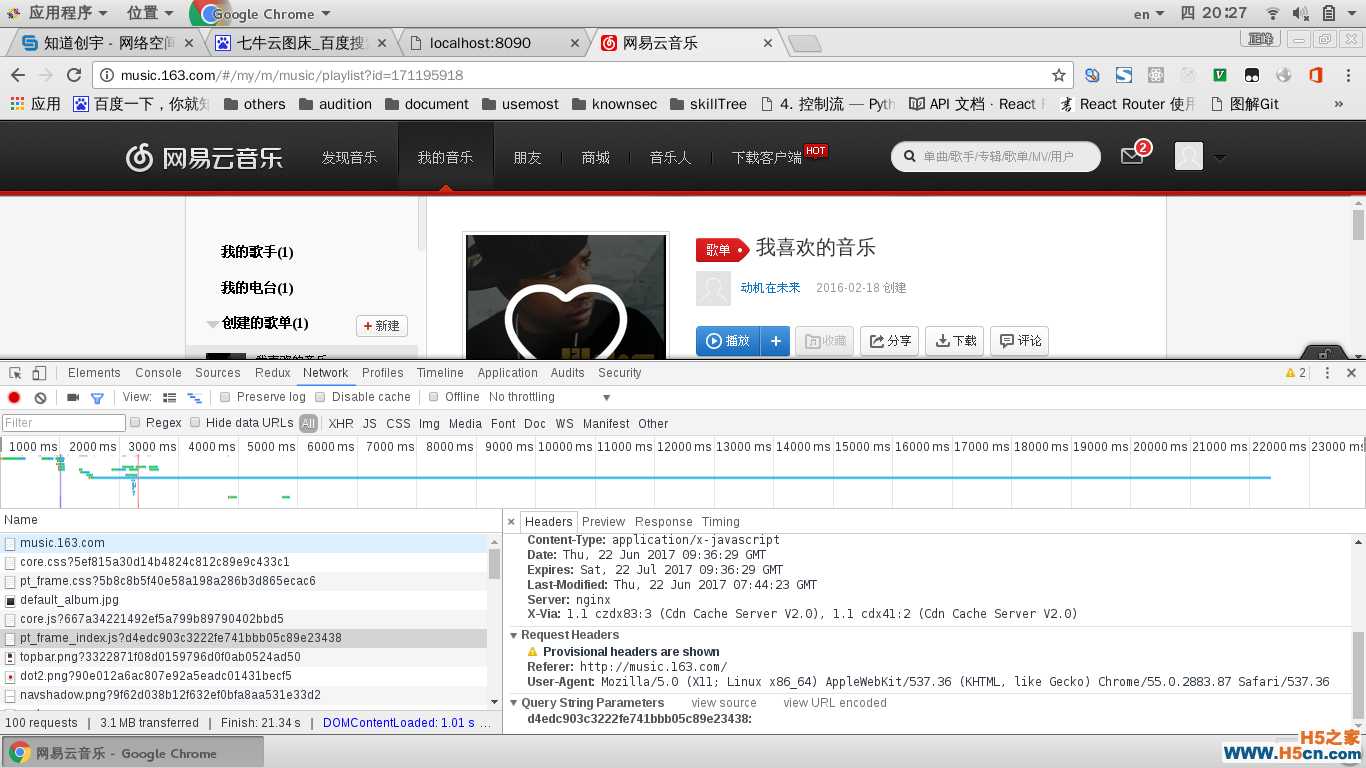
在不断尝试的过程中,珩哥提到,后端获取不到前端的URL地址,是因为react-router路由是使用的hash路由(:3001/#/news/index/4141?_k=mv8udy),如果将hashHistory改为browserHistory(:3001/news/index/4141)的话,那么后端一定就可以获取到前端的URL。
解决方案:
cd projectName/app/src vim app.js // hash路由 import { Router, hashHistory as historyProvider, match } from 'react-router'; // 修改为browserHistory import { Router, browserHistory as historyProvider, match } from 'react-router';进行查看:
主页面:
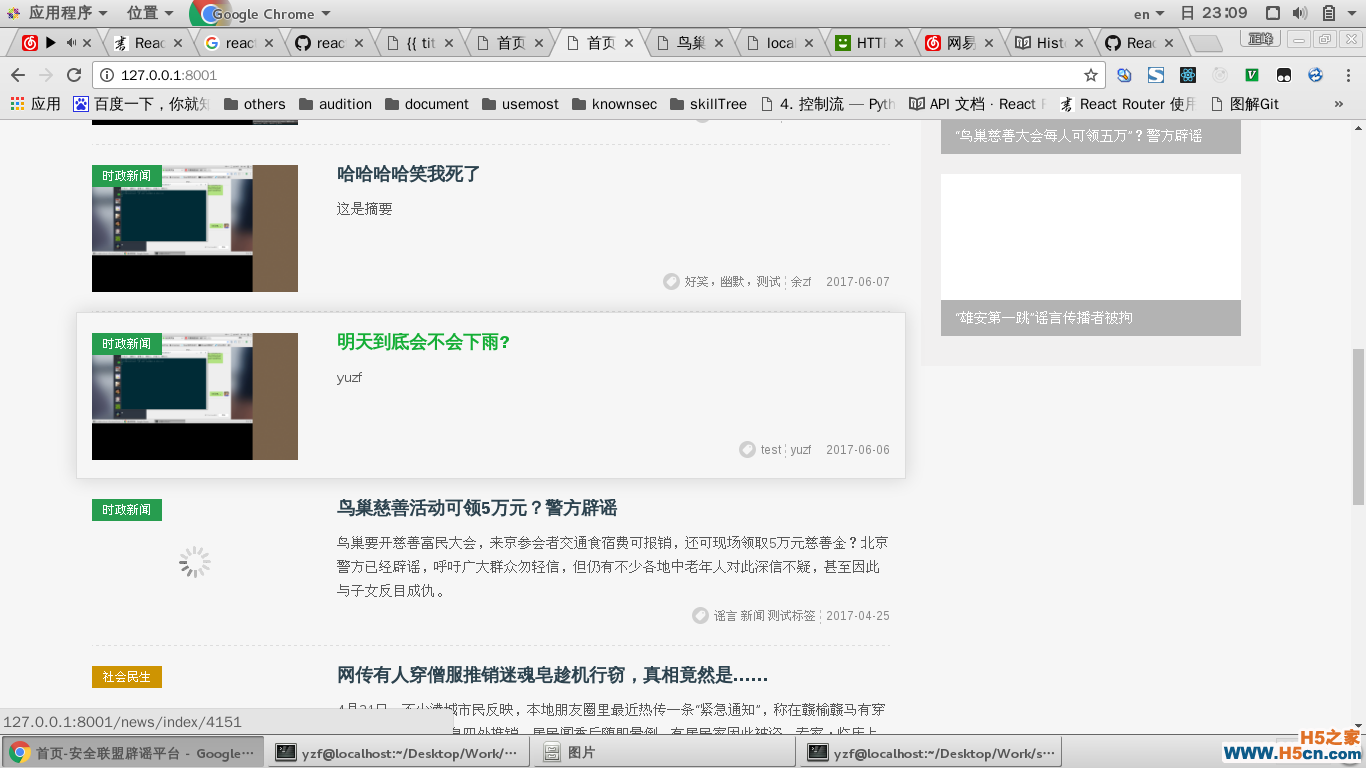
新闻详情页:
那么如何进行测试呢?
其他方案不知道大家是否还有其他解决方案?
原理 History它是一个库,react-router基于它来管理历史会话记录。
简单的说,一个history知道如何去监听浏览器地址栏的变化,并解析这个URL转化为location对象,然后router使用它匹配到路由,最后正确地渲染对应的组件。
常见的3种History BrowserHistory它其实就是HTML5推出的历史记录API,可以把浏览器记录当作一个栈,通过History提供的API来对浏览器记录进行相应的操作。
常见的方法有下面这几种:
BrowserHistory是使用react-router应用推荐的history。它使用浏览器中的HistoryAPI用于处理URL,会创建一个像example.com/some/path这样的真实的URL。
要使用这个History的话,必须在服务器端做好处理URL的准备。一般从下面几个方面来考虑:
处理/的请求, Django简单配置如下:
// urls.py from apps import views urlpatterns = [ url(r'^$', views.index,), ]处理每个URL的路由, 这也是最容易被忽视的一部分。当你在导航栏里点来点去,显示是没有问题的,就像下面这样。
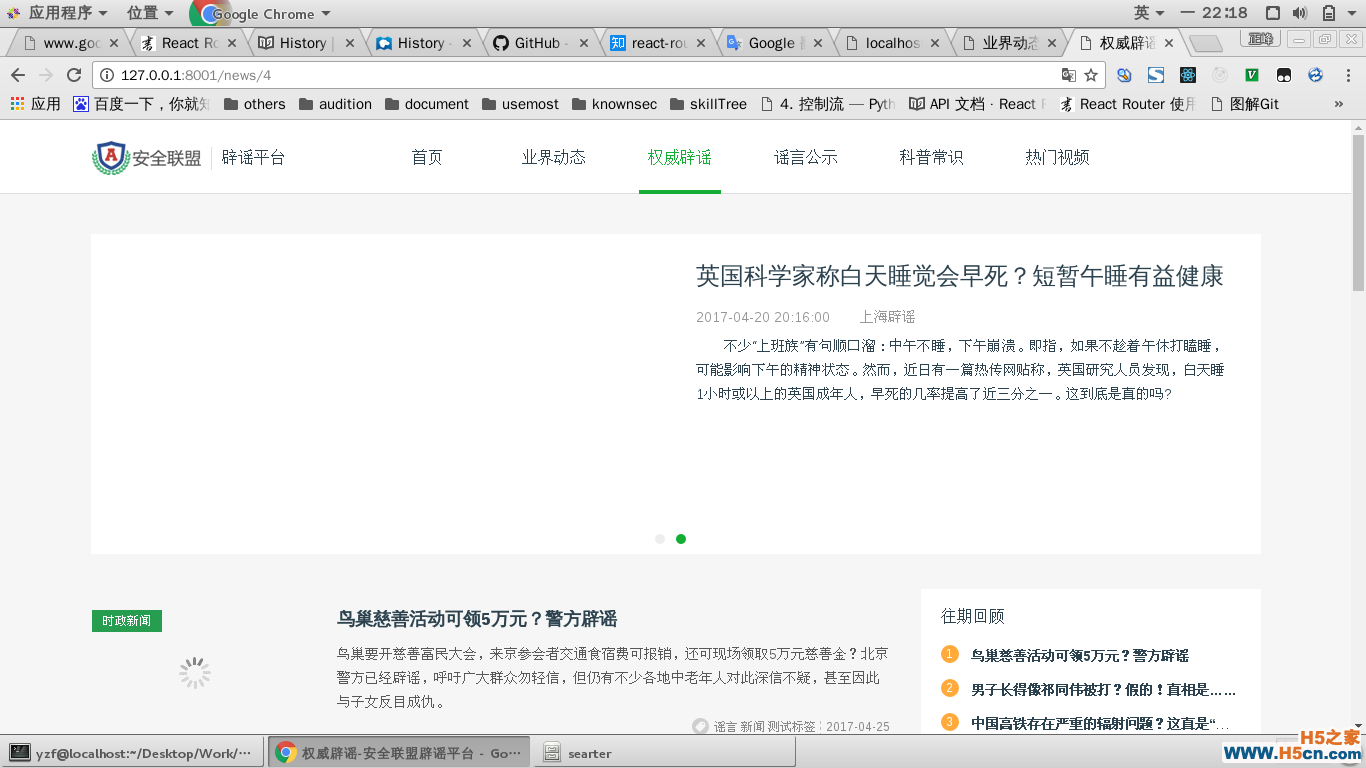
但是当你刷新页面的时候,你会得到这样一个结果:

这是由于,你的应用是单页的,当你点击导航栏的时候,页面并没有刷新,只是JavaScript去请求了后台,然后更新了前端路由和组件状态,但是没有刷新页面,导致没有去请求后台的地址。所以,必须为每个URL在后端配置路由。一般来说,只需要配置简单的根路由就可以了,除非你需要动态更改模板index.html上的数据。
Hash history使用URL中的hash(#)部分去创建形如: example.com/#/path的路由。
像?_k=ckuvip没用的URL是什么东西? MemoryHistoryMemory history不会在地址栏里被操作或读取,这就解释了是如何实现服务端渲染的。
BrowserHistory与HashHistory的对比实际上,两种History都只是人为控制路由的一种手段。
相同点:
它们都只是简单的改变了地址栏里的URL,如果没有刷新页面的话,都不会向后端主动发送请求。
不同点:
当页面刷新的时候,对于BrowserHistory, 浏览器会向后台发送整个URL的请求, 而对于HashHistory, 它只会请求后台的根目录。
使用场景 其他推荐阅读: 关于如何爬取ajax应用
感觉单页的seo,除了用SSR,就没有其他的办法了。
参考react-guide
深入理解react-router
posted @
 相关文章
相关文章 精彩导读
精彩导读
 热门资讯
热门资讯 关注我们
关注我们
