本篇文章写在新春佳节前夕,也是给IT运维朋友一个警醒,在春节长假前请妥善体检自己的系统安心过个年。
千里之堤毁于蚁穴,一条看似简单的语句就能拖垮整个系统,您的SQL Server很久没体检了吧? 就像一块藏着刀片的蛋糕!怎能安度春节?
日志暴增的问题处理过很多,这只是很常规的一次,但是对于不是很熟练的运维兄弟,可能日志暴增这样的问题会被一带而过,或者解释成突发情况而不去处理,那么隐患依然存在,在春节这样的长假发生可怎么办呢?
本文使用的工具:SQL专家云平台专业体检工具 :
场景描述本案例是一个很成熟的ERP厂商的产品,接到用户紧急电话,说他们日志突然暴增磁盘告警,50G的数据库日志已经达到200G。

看到这有的看官可能会说,肯定是没定时做日志备份导致日志不断变大!或者说才200G 一点也不大呀!
没错,日志不备份缺失会有这样的问题,但这情景是小儿科,不会拿出来写案例的,200G 确实也不大,但要分场景,在此客户平均10个G 的场景下 200G已经是爆炸式的问题了!
为什么会拿出来写案例,就是因为想要告诉大家排查这样问题的思路,不要让这样的暴增单纯的说成突发情况!
问题分析拿到收集文件我直入主题,查看日志的增长情况、写入状态、问题时间点等信息
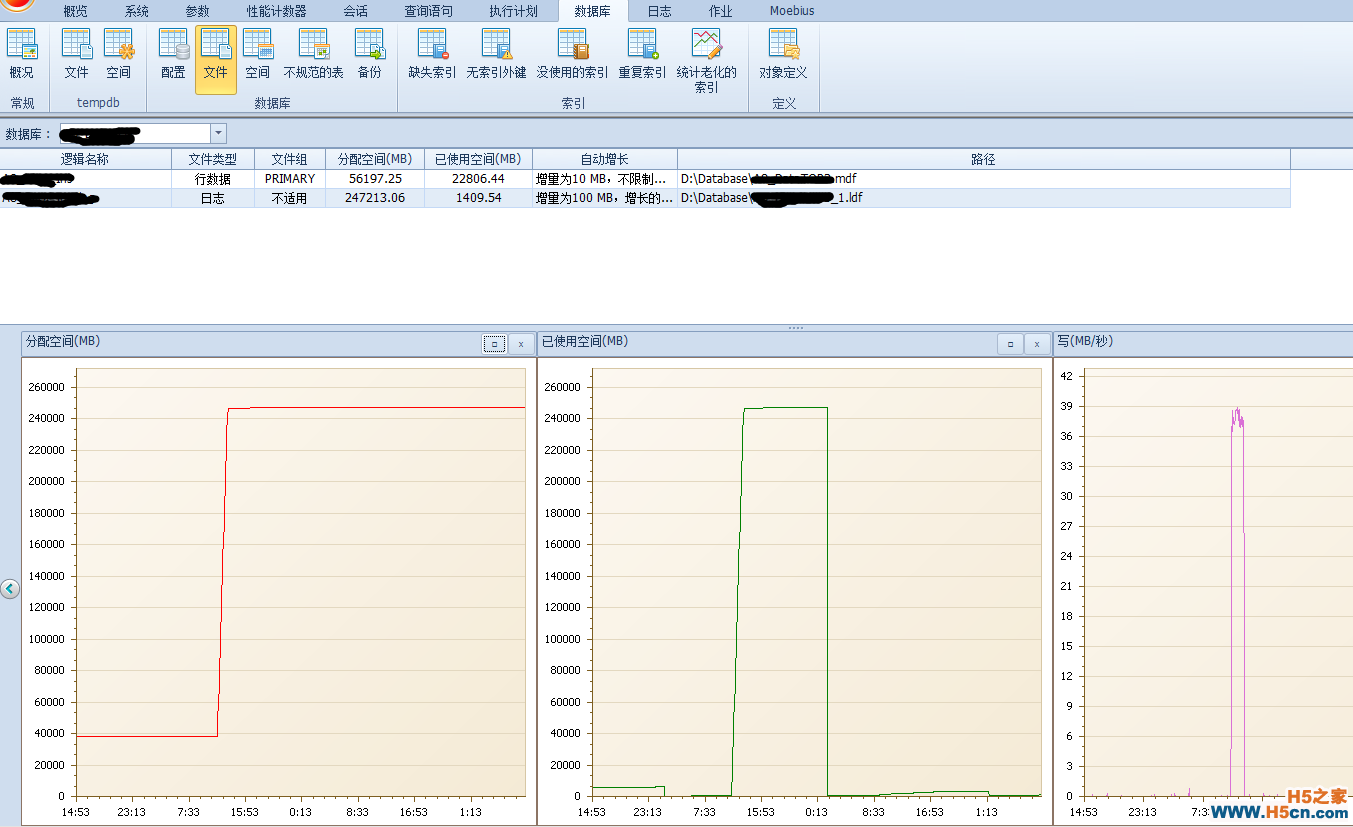
在日志的分配空间我们了解到日志是在11点43分左右突然暴增一直增长到13点左右达到240G

分配空间也是同样的情况在11点43分左右暴增,后期在1点半的下降就是日志备份让使用空间被释放。
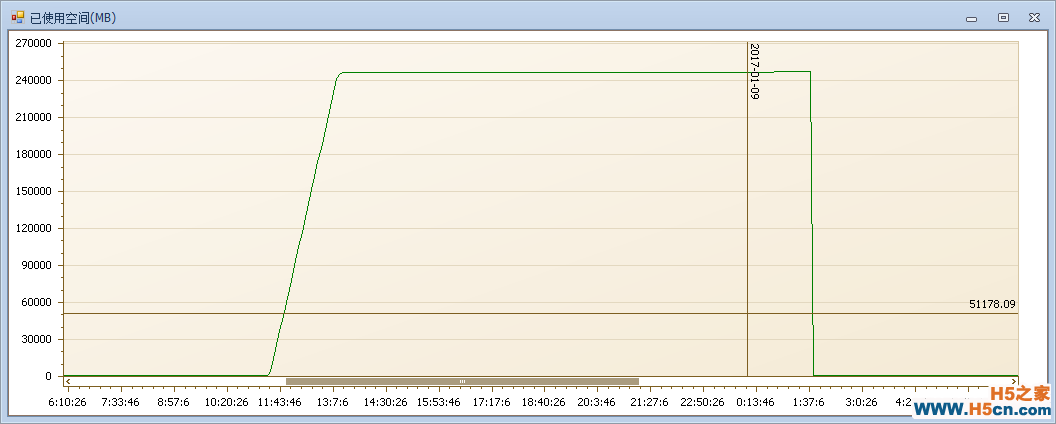
日志文件的写入也符合这个时间点,在11点43分左右写入达到40MB/秒,并且持续了1个多小时。
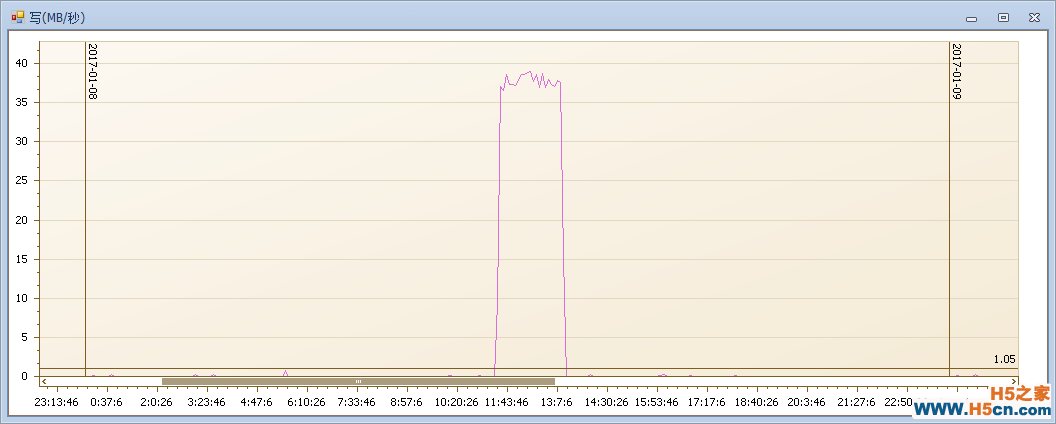
通过这几张图,我们很清晰的就能定位到日志暴增的时间点,下面只要找到对应时间点的语句即可!
我的排查思路有些不同,持续1个小时的写入,必然伴随着日志文件的增长(文件增长设置固定值100MB),这里需要提一下:这就是固定增长的好处,因为当达到240G 如果按照默认10%增长,那么一次需要增24G 磁盘已经没有那么多空间,则会导致报错,系统中断!
回到排查思路,这里我直接查看对应时间点系统的等待情况:

直接找到日志文件增长的等待类型,查看运行的语句确实运行时间是从11点15到13点15,和日志增长的情况吻合!!
就这样,只花了10分钟就定位到问题,找到语句,由于存储过程加密,我无法看到里面的代码,但是暴增的语句已经找到,需要软件厂商自行处理啦!!
就是这样简单,打完收工!所以不要放过这样的问题排查!
后怕为什么说不能放过这样问题的排查!!!
首先,这个系统正准备上集群,集群大家都知道单机变多台,必然涉及到数据的同步,同步是要有消耗的,对写入的性能会有影响,细心的小伙伴可能已经看到这个语句消耗了多少资源,逻辑读,写,影响行数有多少了
没错,64亿的逻辑读!为什么会产生这么大的日志,导致暴增!因为写入1亿次,影响行数19亿,并且执行的时间不是在夜间的维护期,而是在中午11点15开始,这么大的处理在集群方案部署的时候一定要高度警惕,这么大的同步量完全可能导致集群严重延迟,甚至宕机!所以这不单单是一次日志暴增问题的排查了,也是对系统功能更加细致的了解,如果这样的问题没有及早发现,就算集群后期测试也不一定会被测试到,进而导致集群上线后的悲催。
PS:继逻辑读 23亿,34亿,45亿后这个案例有刷新了我见过的最大逻辑读 64亿!
纪念一下
--------------博客地址---------------------------------------------------------------------------------------
博客地址
欢迎转载,请注明出处,谢谢!
-----------------------------------------------------------------------------------------------------
总结系统运维就是保证系统平稳运行的工作,看似简单但个中奥妙和心酸只有运维人才能体会,不要放过每一个细节,一个简单突发情况处理可能引出一系列问题,而解决这些问题又是保证系统平稳运行基础,请给运维人多一些关爱吧,比如春节来个大红包,哇哈哈哈哈!!
有的小伙伴已经开始春节休假了,祝大家新春快乐,系统平安!
----------------------------------------------------------------------------------------------------
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,非常感谢!
 相关文章
相关文章
 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
