在分布式存储系统中,系统可用性是最重要的指标之一,需要保证在机器发生故障时,系统可用性不受影响,为了做到这点,数据就需要保存多个副本,并且多个副本要分布在不同的机器上,只要多个副本的数据是一致的,在机器故障引起某些副本失效时,其它副本仍然能提供服务。本文主要介绍数据备份的方式,以及如何保证多个数据副本的一致性,在系统出现机器或网络故障时,如何保持系统的高可用性。
数据备份数据备份是指存储数据的多个副本,备份方式可以分为热备和冷备,热备是指直接提供服务的备副本,或者在主副本失效时能立即提供服务的备副本,冷备是用于恢复数据的副本,一般通过Dump的方式生成。
数据热备按副本的分布方式可分为同构系统和异步系统。同构系统是把存储节点分成若干组,每组节点存储相同的数据,其中一个主节点,其他为备节点;异构系统是把数据划分成很多分片,每个分片的多个副本分布在不同的存储节点,存储节点之间是异构的,即每个节点存储的数据分片集合都不相同。在同构系统中,只有主节点提供写服务,备节点只提供读服务,每个主节点的备节点数可以不一样,这样在部署上会有更大的灵活性。在异构系统中,所有节点都是可以提供写服务的,并且在某个节点发生故障时,会有多个节点参与故障节点的数据恢复,但这种方式需要比较多的元数据来确定各个分片的主副本所在的节点,数据同步机制也会比较复杂。相比较而言,异构系统能提供更好的写性能,但实现比较复杂,而同构系统架构更简单,部署上也更灵活。鉴于互联网大部分业务场景具有写少读多的特性,我们选择了更易于实现的同构系统的设计。
系统数据备份的架构如下图所示,每个节点代表一台物理机器,所有节点按数据分布划分为多个组,每一组的主备节点存储相同的数据,只有主节点能提供写服务,主节点负责把数据变更同步到所有的备节点,所有节点都能提供读服务。主节点上会分布全量的数据,所以主节点的数量决定了系统能存储的数据量,在系统容量不足时,就需要扩容主节点数量。在系统的处理能力上,如果是写能力不足,只能通过扩容主节点数来解决;而在写能力不足时,则可以通过增加备节点来提升。每个主节点拥有的备节点数量可以不一样,这在各个节点的数据热度不一样时特别有用,可以通过给比较热的节点增加更多的备节点实现用更少的资源来提升系统的处理能力。
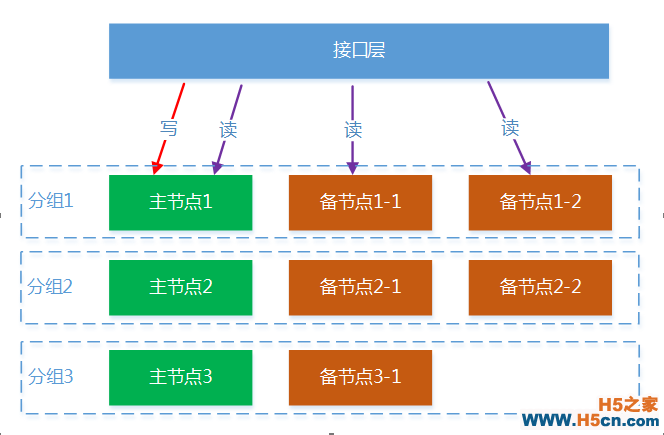
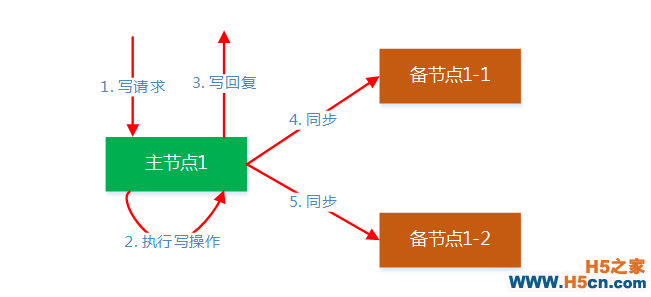
在上面的备份架构中,每个分组只有主节点接收写请求,然后由主节点负责把数据同步到所有的备节点,如下图所示,主节点采用一对多的方式进行同步,相对于级联的方式,这种方式在某个备节点故障时,不会影响其它备节点的同步。在CAP理论中,可用性和一致性是一对矛盾体,在这里主节点执行写操作后会立即回复客户端,然后再异步同步数据到备节点,这样并不能保证主备节点的数据强一致性,主备数据会有短暂的不一致,通过牺牲一定的一致性来保证系统的可用性。在这种机制下,客户端可能在备节点读到老数据,如果业务要求数据强一致性,则可以在读请求中设置只读主选项,这样读请求就会被接口层转发到主节点,这种情况下备节点只用于容灾,不提供服务。
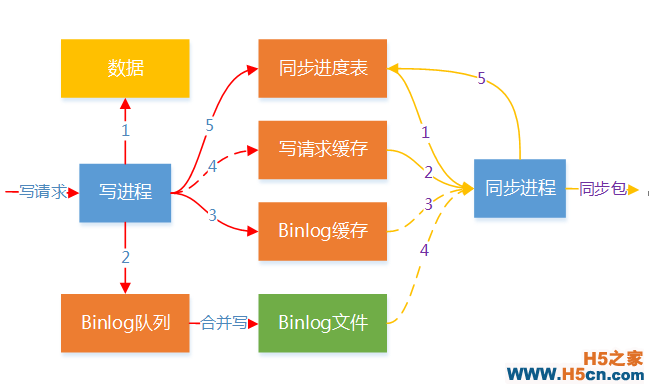
为了保证主备节点的数据一致性,需要一种高效可靠的数据同步机制。同步分为增量同步和全量同步,增量同步是主节点把写请求直接转发到备节点执行,全量同步是主节点把本地的数据发到备节点进行覆盖。接下来详细介绍同步机制的实现,同步的整体流程如下图所示。
系统中数据分片的单位是一致性哈希环中的VNode(虚拟节点),每个VNode有一个自增的同步序列号SyncSeq,VNode中所包含的数据的每一个写操作都会触发它的SyncSeq进行自增,这样在每个VNode内SyncSeq就标识了每一次写操作,并且SyncSeq的大小也反映了写操作的执行顺序。数据的每次写操作除了修改数据,还会保存写操作对应的SyncSeq,后面可以看到,SyncSeq是同步机制可靠性的基础。
主节点的写进程收到写请求后,先修改数据,把当前VNode的SyncSeq加1并更新到数据中。接下来会记录Binlog,Binlog是一个三元组<VNode, SyncSeq, Key>,可以唯一标识整个系统的一次写操作。Binlog会写入到Binlog队列和Binlog缓存,Binlog队列由其他进程合并写入到Binlog文件,Binlog缓存是一个可淘汰的哈希表,用于快速查找。然后把写请求缓存在一个可淘汰的哈希表中,写请求用于进行增量同步,哈希表存储了三元组<VNode, SyncSeq, Req>,这里缓存的写请求包大小有限制,超过限制的写请求不进行缓存。 最后写进程会更新同步进度表,如下图所示,同步进度表记录了各个VNode主节点同步到各个备节点的进度,主节点的SyncSeq是各个VNode最后一次写操作的SyncSeq,备节点的SyncSeq是已同步的最大的SyncSeq。
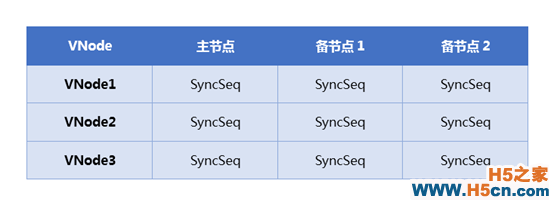
主备节点的数据同步由主节点上的同步进程异步进行,通过扫描上图的同步进度表中主备节点的SyncSeq差异就可知备节点需要同步哪些数据。同步进程通过同步进度表确定需要同步的二元组<VNode, SyncSeq>,先去写请求缓存中查找,如果找到,则把写请求发给备节点进行增量同步。如果在写请求缓存中未找到,则依次去Binlog缓存和Binlog文件中查找对应的Binlog,通过Binlog对数据进行全量同步。最后再更新同步进度表中已同步的备节点SyncSeq,至此一个完整的数据同步流程已经完成。
接下来介绍一下同步协议如何保证同步的高效和可靠。为了让同步包严格按照主节点的发送顺序到达备节点,采用TCP协议进行同步,在主节点的每个VNode上到每一个备节点建立一个TCP连接,记为一个同步连接。在每一个同步连接上,主节点会一次性批量发送多个同步包,备节点也会记录已同步的SyncSeq,对每一个同步包会检查携带的SyncSeq是否符合预期,如果符合预期,则执行同步写操作,执行成功是更新已同步的SyncSeq,在这种情况写备节点也不需要回应主节点,主节点在未收到备节点的回应时,会认为同步一切正常。只有以下异常情况下,备节点才会回应主节点:
 相关文章
相关文章

 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
