上网简单看了几篇博客
自己试了试简单的爬虫
哎呦喂
很有感觉
蛮好玩的
之前写博客 有点感觉是在写教程啊什么的
写的很别扭
各种复制粘贴
写得很不舒服
以后还是怎么舒服怎么写
把每天的练习
所得
写上来就好了
本来就是个菜鸟
不断学习
不断debug就好
直接上程序:
urllib2 3 import urllib 4 import re pat = re.compile() ) ) ) ) nexturl = SerialNumber = [] 17 nexturl1 = nexturl + SerialNumber[0] s(nexturl2): 23 myurl = nexturl2 values = {: , : } : user_agent } 27 data = urllib.urlencode(values) 28 request = urllib2.Request(myurl, data, headers) 29 myres = urllib2.urlopen(request) 30 return myres 31 32 myres = s(nexturl1) 33 mypage = myres.read() ) total = pattotal.findall(ucpage) num = patnum.findall(ucpage) umax = raw_input() 43 44 picnum = 1 int(picnum) <= int(max): int(total[0]) == int(num[0]): SerialNumber = patnextgroup.findall(ucpage) 51 nexturl1 = nexturl + SerialNumber[0] 52 53 myres = s(nexturl1) 54 55 mypage = myres.read() ) SerialNumber = patnext.findall(ucpage) 58 59 total = pattotal.findall(ucpage) 60 num = patnum.findall(ucpage) 61 62 mat = pat.findall(ucpage) len(mat) : + str(picnum) + + mat[0] + fnp = re.compile() 68 fnr = fnp.findall(mat[0]) 69 if fnr: urllib.urlretrieve(mat[0], fname) picnum+=1 : u
程序抓取的是 的图片
抓取完一张
就申请进入下一页继续抓取
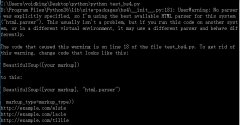
运行结果:


收获:
1.html js 不熟悉
2.可以通过找URL直接的规律 找下一页的URL
3.查了些资料 发现很多东西都可以学 html js beautiful soup等
4.还没习惯用try 语句
5.多练多学多问
6,urllib.urlretrieve() mypage.decode("gbk")
遇到的困难:
1.一开始不知道下一页的链接在哪 找了很久才找到 但方法不对 不知道有什么好的方法 一个原因是不了解 html js
2.一开始不知道怎么“变”到下一页,所以还想着通过pymouse控制鼠标。。。。。。结果鼠标不受控制 暴力重启。。。
3.运行的时候会跳出这个问题:IOError: [Errno socket error] [Errno 10060],为什么呢?还需要设置什么?求大神帮忙解决
 相关文章
相关文章

 精彩导读
精彩导读
 热门资讯
热门资讯 关注我们
关注我们
