从上面2个例子的测试结果可以看到,python的一些基本类型通过encode之后,tuple类型就转成了list类型了,再将其转回为python对象时,list类型也并没有转回成tuple类型,而且编码格式也发生了变化,变成了Unicode编码。具体转化时,类型变化规则如下所示:
Python-->Json

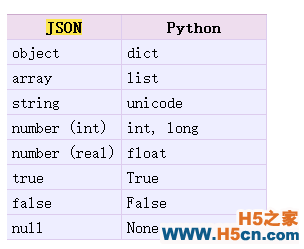
Json-->Python
Json处理中文问题:
关于python字符串的处理问题,如果深入的研究下去,我觉得可以写2篇文章了(实际上自己还没整很明白),在这里主要还是总结下使用python2.7.11处理json数据的问题。前期做接口测试,处理最多的事情就是,把数据组装成各种协议的报文,然后发送出去。然后对返回的报文进行解析,后面就遇到将数据封装在json内嵌入在http的body内发送到web服务器,然后服务器处理完后,返回json数据结果的问题。在这里面就需要考虑json里有中文数据,怎么进行组装和怎么进行解析,以下是基础学习的一点总结:
第一:Python 2.7.11的默认编码格式是ascii编码,而python3的已经是unicode,在学习编解码的时,有出现乱码的问题,也有出现list或者dictionary或者tuple类型内的中文显示为unicode的问题。出现乱码的时候,应该先看下当前字符编码格式是什么,再看下当前文件编码格式是什么,或者没有设置文件格式时,查看下IDE的默认编码格式是什么。最推崇的方式当然是每次编码,都对文件编码格式进行指定,如在文件前 设置# coding= utf-8。
第二:字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312‘),表示将gb2312编码的字符串str1转换成unicode编码。encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312‘),表示将unicode编码的字符串str2转换成gb2312编码。因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码
第三:将json数据转换成python数据后,一般会得到一个dict类型的变量,此时内部的数据都是unicode编码,所以中文的显示看着很痛苦,但是对于dict得到每个key的value后,中文就能正常显示了,如下所示:
# coding= utf-8 import json import sys if __name__ == ‘__main__‘: # 将python对象test转换json对象 test = {"username":"测试","age":16} print type(test) python_to_json = json.dumps(test,ensure_ascii=False) print python_to_json print type(python_to_json) # 将json对象转换成python对象 json_to_python = json.loads(python_to_json) print type(json_to_python) print json_to_python[‘username‘]
运行结果:

python 学习(json)(转)
标签:bar asc 复制 深入 处理中文 oat 问题 封装 decode
原文:
 相关文章
相关文章
![JsBin[使用教程]](/upload8/allimg/161017/13023G619_lit.png)
 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
